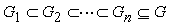 each one
representing a more precise approximation to the whole graph G.
each one
representing a more precise approximation to the whole graph G.
Abstract: Most search
engines exploit spiders to implement the information gathering
process. We present a technique to reduce the memory resources
required by such spiders, improve the coverage and to provide
for scaling through parallelization. The technique exploits the
direct enumeration of Internet hosts through Domain Name Server.
Tool bases on this technique have been successfully applied in
a search engine for the ".it" domain but can be applied
directly to other domains. We report statistics on the results
of the use of our tools in this context.
Web robots are tools used to gather data from the
Web [De Bra 1996]. Robot behaviour may be formally described by
means of an oriented graph G = (N, A), where N
is a finite set of nodes, corresponding to Web documents uniquely
specified through their URL, and A is the set of arcs which
represent unidirectional pointers, corresponding to the links
between documents. G does not have to be fully interconnected
since there can be URLs not reachable from other URLs: on Internet
there can be a Web server completely autonomous defining a subgraph
without any incoming arcs. A more appropriate model for the highly
irregular World Wide Web is hence a set of connected components.
The task of a robot is to visit each node in G
once avoiding to traverse twice the same path. This is done by
building a sequence of graphs each one
representing a more precise approximation to the whole graph G.
The two main visit techniques are: the Depth-First-Search
(DFS) and the Breadth-First-Search (BFS). With the first method,
when a node is visited, we go away from it as much as we can until
a blind alley is found (a node v all of whose adjacent
nodes have already been visited). The order of visit is FIFO and
the algorithm may, as a consequence, activate a recursive process
whose depth is related to the length of the most extended not-cyclic
path present on the Web. The second method, instead, visits the
nodes according to the growing distance d from the start
node r, where the distance between r and the generic
node v is the length of the shortest path from r
to v. The order of visit followed is, in this case, LIFO.
Often the two techniques are combined: a set of starting
points for the search is built by performing a BFS with maximum
distance from a root, and then DFS is applied from this set. All
the other methods are variants of combinations of BFS and DFS.
Note that the whole graph G is not known a
priori. New nodes are added each time an already acquired arc
is followed, building a new graph Gi from the
given Gi-1.
An analysis of the above algorithms leads us to reveal some limits:
We present some tools we developed for enumerating hosts and facilitating Web search. These tools are used in ARIANNA[], an Internet search engine for Web sites with italian language content. Since some hosts with italian language content do not appear under the ".it" DNS domain, several heuristics, whose discussion is beyond the scope of this paper, have been employed in order to find them.
The method we implemented exploits the fact that many problems that affect the Web visit algorithms, may be solved by building a priori an URLs list that must be the widest possible. Each item is used as a starting point for a distinct robot. Similar techniques have already been proposed and a list of them is presented in [DeBra 1996]. However, most of these are ad hoc and not general enough. For example one suggestion is to survey Usenet News postings in order to discover URLs. An important aspect of the method we propose is to be parametric: different selection criteria give rise to a spectrum of solutions. A very selective criterion, even though it reduces the indexing time, could discard valid hosts; a weak selective criterion, on the other hand, could show the opposite behaviour.
The WWW structure is inherently chaotic. The final aim of BFS and DFS algorithms is to build a spanning tree for the connected components of the Web. A spanning tree suggests the idea to find a way of hierarchical ordering net hosts. Luckily, this ordering can be derived from the domain subdivision provided by the DNS system [Albiz & Liu 1996]. Using tools like host or nslookup and directly querying authoritative nameservers one can find the set of host names H(Di) = {hd1, …, hdi} inside the domain Di. Let D = {D1, …, Dz} be the set containing all Internet domains and let H be set of all Internet hosts defined as follows:
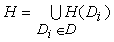
Let n = #(H), R robots (with R << n) can be used to examine the n found hosts in parallel using DFS or BFS techniques (or their variants). Since not all Internet hosts have a WWW server, assigning to a robot a machine that contains nothing to be indexed is a waste of time and could invalidate any balancing policy. The compromise we adopted is to preselect all Internet hosts having a canonical name (record A) or an alias (CNAME) among those most commonly used for machines running WWW services. In detail, we define a criterion K according to which a host becomes candidate to be indexed: for instance we can test whether its name contains "www", "web", "w3" as substrings. Let W be the set of all hosts satisfying K:
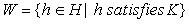
Let Q = (P1, … , PR)
be a partition of W: the indexing domain DI(r),
assigned to a robot (with 1 r R) is defined as
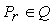 .
.
Our method has the following properties:
A further optimization allows avoiding direct query
to an authoritative nameserver for each domain in order to build
the set H. To reach this aim the RIPE[] monthly survey
(hostcount) is exploited. This has the advantage of saving
bandwidth: one avoids building the Italian domain topology since
it is already available on Internet. [Tab. 1] reports the results
obtained applying criterion K on the hostcount for
the italian domain. However, this improvement has introduced two
problems. Let HRIPE be the host used by RIPE
to survey the net and let NS(D) = {NSP(D),
NSS1(D)) …, NSSj(D)}
be the set formed by the primary nameserver and by j secondary
nameservers for domain D. It can happen that:
If one of these conditions occurs during analysis
of domain Di, hostcount omits from the
survey both Di and all domains delegated by
the authoritative nameservers for Di. Note that
(1) and (2) might not happen if the queries to NS(D)
are performed from a host different from HRIPE.
In such cases, one could discover the domain structure even if
it is not present in hostcount. Statistical studies (reported
in [Tab. 2] ) justify this corrective intervention: in fact for
domain ".it" our method counts a number of machines
that is more than 10% greater than that contained in the RIPE
database.
Once the set of the hosts in W has been built, in order to determine those which are actual Web servers, we have developed testwww, an agent which tests the presence of a HTTP server on a set of TCP ports chosen among those generally used to provide such service. testwww was tested on more than 14000 Italian hosts [Tab. 3]. Let T be the set built from W using testwww:
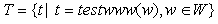
We then partition T into R subsets
(P1, … , PR) as above
and assign a robot r to each Pi = DI(r).
During the analysis of host h DI(r),
the path memory for robot r is limited to the documents
contained in h. This provides scalability for performing
parallel indexing in a search engine.
Besides, testwww allows us to build statistics on [Tab. 4]:
Some HTTPD daemons provide several virtual Web servers
on the same IP address. This is known as VIRTUAL HOSTING: the
administration job is centralized while the content of each virtual
site is under the responsibility of its respective owner. A single
IP address is used but each virtual site has assigned a CNAME
(or an A record on the same IP). Virtual Hosting was standardized
in version 1.1 of HTTP protocol [Berners-Lee,
Fielding & Frystyk 1996]. This requires
a revision of robot's visiting algorithms. Indeed, if path memory
is managed only according already visited IP addresses, documents
with the same document path but located on distinct virtual servers
will be missed.
We solved this problem using a heuristic: the testwww agent, given a set of A and CNAME records N(host) = { A1, … , Ap , C1, … , Cq } associated via DNS to net address Ihost, contacts (p + q) times the HTTP server on Ihost asking for the Document Root, with a different argument for the "Host:" directive chosen from N(host). For each returned page, testwww computes a MD5 RSA [Schneier 1996] signature. Two Web servers are considered distinct if and only if they have different associated signatures. This is well represented by the set M:
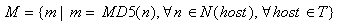
To perform the partitioning of hosts into indexing
domains we decided to exploit the division into Autonomous Systems
(AS). The idea is to minimize the number of border gateways (according
to BGP4 terminology [Huitema 1995])
crossed during the indexing phase in order to reduce the probability
of using links with high traffic load.
For the case of the italian domain we chose three indexing hosts, each one in a different AS. The prtraceroute tool [PRIDE 1996] tells us to for each host, both which AS it belongs to and how many AS are crossed to reach it. We then filter static information given by the RIPE Registration Authority (via whois) in order to assign hosts to the indexing points so that the number of crossed border gateways is minimized and therefore the indexing time is reduced.
In summary our method has the following features:
As it may be expected there also are some limits:
the most evident one is that we miss Web servers not satisfying
the K criterion. Several approaches are possible to mitigate
this drawback although we expect it not to be significant. Statistical
data (reported in [Tab. 5]) show that we collect a remarkable
number of URLs compared to similar engines based on traditional
spider mechanisms: ARIANNA is currently the most complete Italian
search engine in terms of indexed information.
A first method to discover a host not satisfying
the criterion K is based on a different way of integrating
DNS enumeration techniques with visit algorithms. Once an indexing
domain DI(r) = { H1, … ,
Hl } has been built, each robot is allowed to
cross not only the host Hi (with i <
l) but also all hosts in the same DNS domain. In this case
the path memory of each robot is now limited to WWW pages contained
in the Web servers of the examined DNS domain. Careful partition
that doesn't assign to different robots the same DNS domain allows
us to reach scalability for parallel indexing. Alternatively the
method may use as a boundary the IP classes.
A second method is based on post processing the already collected Web pages when the indexing phase is ended. This is done in order to discover news URLs not enumerated in the set W. Note that this is a local job (not involving communication) and as consequence less time-consuming.
We report statistical data which refer to the use
of our tools within the ARIANNA search engine.
| 6995 | 8608 | |||
| 6932 | 8573 |
| 646 | 464 | |||
| 248 | 364 | |||
| 484 | 401 |
| 1231 | 738 | |||
| 513 | 134 |
| 8228 | 14431 | |||
| 7440 | 13780 | |||
| 6741 | 11045 | |||
| 424 |
| 6.629 | 8.134 | |||
| 1.351.442 | 2.095.318 | |||
| 10.151.481 | 7.558.919 | |||
| 6.932.135 | 9.879.552 | |||
| 17.187 | 127.173 | |||
| 2 hours | 2 hours | |||
| 15 days | 20 days |
The work described here was done within the cooperation between SerRA, Università di Pisa and OTM Interactive Telemedia Labs. We would like to thank A. Converti, L. Madella, A. Vaccari and G. Antichi of the OTM labs for their support.
[Albiz and Liu 1996] Albitz, P., & Liu, C. (1996).
DNS and BIND 2nd Edition. O'Reilly & Associates.
[PRIDE 1996] PRIDE - Policy based Routing Implementation
Deployment in Europe, ftp://ftp.ripe.net/pride/
[DeBra 1996] De Bra, P.M.E (1996). Introduction to
WWW Robot Technology, 5th International World Wide Web Conference.
O'Reilly & Associates.
[Eichmann 1994] Eichmann, D. (1994). The RBSE Spider-Balancing
Effective Search Against Web Load, First WWW Conference.
[Berners-Lee, Fielding and Frystyk 1996] Berners-Lee
T., Fielding R., Frystyk H. (1996). Hypertext Transfer Protocol
- HTTP/1.1 - RFC 2068.
[Huitema 1995] Hiutema, C. (1995). Routing In The
Internet. Prentice Hall.
[Schneier 1996] Schneier, B. (1996). Applied Cryptography, John Wiley, 2nd edition.