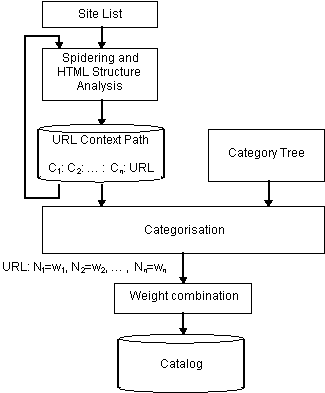
Figura 2.1 Architecture of Categorisation by Context
Most search engines perform search based on the content of documents and provide results as a linear list of documents sometimes ranked in order of relevance. This is often unsatisfactory because the list can be quite long, with many replications, and without any indication of possible grouping of related material. For instance, searching documents with the keyword ìgarbageî, one would obtain a list of documents which discuss ecological issues interspersed with documents about garbage collection in programming languages. Splitting the documents into categories would significantly facilitate selecting those we are interested in.
Notable exceptions are Lycos [Lycos] and Yahoo [Yahoo], which maintain a categorisation of part of their search material (actually Yahoo gave up its search engine in favour of Altavista [Altavista]). However Lycos is based on manual categorisation performed by a small set of well trained technicians. It is questionable whether this approach will scale well with the growth of the Web which will reach over 30 terabytes within 2 years, a size larger than the whole US Library of Congress.
The consistency of categorisation is hard to maintain when different people are involved and the task of defining the categories is also difficult and subjective. For example, documents relating to ActiveX technology are hard to categorise: they might fall within operating systems or within graphics or within object-oriented programming. None of these classifications is satisfactory, since they will miss to establish close connections with other related technologies, like CORBA, JavaBeans, etc. In this case it seems that a new category is emerging ("Software Components") which is not currently envisaged. In fact, by browsing the Web, we may discover several pages which contain references to documents relating to these subjects: each such page in fact determines a context for these documents. Exploiting these contexts, an agent should be capable of creating the appropriate category and to discriminate between documents falling within different categories.
A similar problem arises in the organisation of personal material, for instance mail and bookmarks [Maarek 96] and [Weiss 96].
In this paper we investigate the technique of categorisation by context, where we use the context present in HTML documents to extract useful information for classifying the documents they refer to. This technique is complementary to the traditional technique of classification by content, which extracts information for indexing a document from the document itself. Such approach exploits linguistic analysis to determine relevant portions of the text and statistical analysis to perform feature selection and to determine weighted term features [Fuhr 91]. Categorisation by context instead exploits relevance hints which are directly provided in the structure of the HTML documents which people build on the Web. Combining a large number of such hints, a high degree of accuracy can be achieved.
Another big advantage of context-base indexing is that it can be applied to multimedia material, including images, audio and video [Shrihari 95].
Furthermore, the mechanism that we will describe can be used to restructure a catalogue: in fact the classification is performed with respect to a base catalogue hierarchy. Therefore, supplying a different catalogue hierarchy will produce a new classification. This is quite useful in the non infrequent case when one discovers that a certain classification is no longer appropriate. Normally a re-classification requires significant effort and one tries to avoid it. The technique of categorisation by context provides an automatic tool for doing it.
In particular, the technique can be applied within EUROsearch for multicultural categorisation, since it will allow transferring material from the catalogue in one language into that for another language, which will reflect a different culture.
Categorisation by context leverages on the categorisation activity that users implicitly perform when they place or refer documents on the Web, turning categorisation, form an activity delegated to a restricted number of specialists, into a collaborative effort of a community of users. By restricting the analysis to the documents used by a group of people, one can build a classification which is tuned to the need of that group.
Vistabar [Marais 97] is a desktop assistant for Web browsing which provides a function to retrieve pages which refer to the current document as a mean to find out what people think about a document. Vistabar has also a classification tool, which uses the Yahoo classification tree. A category profiles is precomputed for each category and Vistabar performs a traditional vector-space matching on the word frequencies of a document, exploiting however the hierarchy of classification to prune the search. Vistabar also allows sharing categorisation and annotations by a group of users.
Purcell and Shortliffe [Shortliffe 95] discuss the shortcomings of traditional retrieval systems and describe a context-based technique applied in the medical domain.
WebTagger [Mathe 97] is a personal bookmarking service that provides both individuals and groups with a customisable means of organising and accessing Web-based information resources. In addition, the service enables users to supply feedback on the utility of these resources relative to their information needs, and provides dynamically-updated ranking of resources based on incremental user feedback.
The overall architecture of the task of categorisation
by context is described in the following figure.
This task starts from list of URLs, retrieves each document, analyses the structure of the document in terms of its HTML tags.
The tags considered are currently: <TITLE>, <Hn>, <UL>, <DL>, <OL>, <A>. Whenever one of these tags is found, a context phrase is recorded, which consists of the title within a pair <Hn> </Hn>, or the first portion of text after a <UL> or <DL> tag, or the phrase within an <A> tag. When a <A> tag is found containing an URL, an URL Context Path (C1: C2 : … : Cn: URL) is produced, which consists of the sequence of the context strings so far (C1: C2 : … : Cn) associated to the URL. Therefore Cn is the text in the anchor of the URL, and the other Ci are the enclosing contexts in nesting order.
In the analysis tags related to layout or highlight (<EM>, <B>, <CENTER>, <FONT> etc.) are discarded.
Another possible element for context is the title of a column or row in a table: tag <TH>. Such title can be effectively used as a context for the elements in the corresponding column or row.
For example, consider the following fragment of an
HTML page from Yahoo!:
"Yahoo! - Science:Biology" :
"information about
specimens in biological collections, taxonomic authority files,
directories of biologists, reports by various standards bodies,
and more"Biodiversity and Biological Collections"
"http://muse.bio.cornell.edu/"
"Yahoo! - Science:Biology" :
"many biology databases,
library and literature links""Biologist's Control Panel"
"http://gc.bcm.tmc.edu:8088/bio/bio_home.html"
"Yahoo! - Science:Biology" :
"a collection of useful
search engines for biological databases on the Internet, accessed
through either the Web or gopher""Biologists Search
Palette"
"http://www.molbiol.ox.ac.uk/www/ewan/palette.html"
The categorisation tasks exploits the database of URL Context Path and the Category Tree within which the URL must be categorised. The Category Tree consists of a tree (or a DAG), where each node contains a single word or phrase which identifies the category.
The goal of the categorisation is to find the most appropriate categories under which an URL should be classified. The output of the categorisation is a sequence of weights associated to each node in the Category Tree:
URL: N1=w1, N2=w2, … , Nn=wn
Each weight wi represents the likelihood that the URL should belong to the category represented by node Ni.
The weights from the Context Path for a URL are added with all other Context Paths for the same URL and normalised. If the weight for a node is greater than a certain threshold, the URL is classified under that node.
The mechanism should allow for classifying an URL under more than one node, but never in two nodes which are descendant of one another.
The classification algorithm considers each node
in the Category Tree as a path. For instance, the following part
of the Arianna category tree
(Arianna [Arianna] is a search engine for the italian Web space
that we are using for our experiments):
corresponds to the following paths, translated into
english:
Notice that the category Events appears in several top level categories, therefore the title of the category is not sufficient to identify the category: the whole path is necessary to disambiguate among the categories. Notice also that we split into two paths any title which contains two terms joined by "e", which literally means "and" but corresponds to the union of the categories, rather than their intersection.
The categorisation algorithm works as follows: first it computes candidate paths for classifying an URL, then it selects among candidates, and finally updates the catalogue.
Given an URL context path (C1: C2 : … : Cn: URL), it considers in turn each Ci, starting from Cn. To each level we associate a weight wl, decreasing from Cn = 1, for instance with a value 1/log2(n - l + 2). It may be worthwhile to adapt these weights take into account the relevance of a tag, for instance a <TITLE> tag may have a slightly higher weight than its position would imply.
It considers the words t1, t2, … , tk, which appear in Ci. The words are analysed to determine their syntactic category, in particular nouns and adjectives. Words which are neither nouns nor adjectives are discarded. The nouns are considered to contribute more to the categorisation and therefore are given a discrimination weight dwnoun (currently 1), while adjectives a lower weight dwadjective (currently 0.5). In the future we should consider grouping adjectives with the noun they refer to.
For each path p in the Context Tree, we create an estimate record pr with as many fields as the path length, initialised to 0.
Each word ti is looked up in each path, and its contribution to the path is computed as follows:
This step is repeated for each level 1 < l < n. morph(t) is the result of applying morphologic normalisation to word t.
Notice that since there can be several matching, the value in a field of a path estimate record can be grater than one, therefore these values should be normalised before performing comparisons.
Any path estimate record pr which contains non zero fields is considered as a potential candidate. The selection among these candidates is performed as follows:
The selected estimate records are stored in the data
base, associated to the URL. When the same URL is reached form
a different path, the new estimates are combined to the previous
ones. This will either enforce the indication of the category
for a URL or suggest alternative categories for the URL.
A prototype classifier by context has been built in order to verify the validity of the method.
An HTML structure analyser has been built in Perl, derived from the analyser used in Harvest.
A spidering program has been written in Java, which uses the HTML analyser to produce a temporary file of URL Context Paths.
A classifier program has been written in Java, which interfaces to WordNet [WordNet] to perform morphing of the words appearing in the context paths and other linguistic analysis.
We have used the Arianna [Arianna] categories for the experiment, translating into english their names, and we tried to classify a portion of Yahoo [Yahoo].
We show the results of categorisation for the first
few items present in the page http://www.yahoo.com/Science/Biology:
Here are candidate paths for the first URL http://esg-www.mit.edu:8001/esgbio:
The grading of candidates for http://esg-www.mit.edu:8001/esgbio
produces the following:
Here is the result for the categorisation of one URL from page http://www.yahoo.com/Regional/Countries/Italy/Recreation_and_Sports/Sports/Soccer/Clubs_and_Teams.
Here are candidate paths for the URL http://www.dimi.uniud.it/~cdellagi:
sport ...........................................
2.0
sport : individual ..............................
2.0 0.0
sport : team ....................................
2.0 3.0
sport : club ....................................
2.0 1.0
sport : event ...................................
2.0 0.0
sport : news ....................................
2.0 0.0
sport ...........................................
2.0
sport : individual ..............................
1.0
sport : team ....................................
2.5
sport : club ....................................
1.5
sport : event ...................................
1.0
sport : news ....................................
1.0
In this experiment we didn't use yet either the synonyms or the related terms. Notice also that since we are using only morphing and not stemming, words such as "biological" do not match with the category "Biology".
There are two ways to use the synonyms: using WordNet to get the synonym of a term in the context, or computing in advance the synonyms for each category and comparing the term with each of them. In principle the two approaches should be equivalent (since the relation synonym is symmetric), but the second should be more efficient. We need to experiment to determine the difference of the two approaches.
Another problem is dealing with categories expressed by a combination of words, such as "commercial service". Our present solution is to look for the presence of a term in the category title: if a match is found, then all other words in the title of the category are checked for presence in the context.
One further problem is to avoid following or categorising URLs that are links to scripts.
We have not exploited yet the hierarchy of concepts provided by WordNet, neither the synsets (synonym sets), lists of synonymous word forms that are interchangeable in some context.
Despite the limitation of the current prototype, the result are quite encouraging. In all the cases we examined the prototype was able to classify each URL in the most appropriate category.
Further experimentation should lead us to determine which facilities provided by WordNet are relevant to our task, in order to produce a list of requirements for a minimal italian version of WordNet, for the purposes of classification by context.
There are two possible cases when one might feel the need to extend the categories in the Catalog:
In order to deal with these problems, the Context Paths should be analysed further.
In both cases, the Context Path for documents in a single large category should be searched for terms in the context which produce partitions of the URLs. Such partitioning terms should be considered as candidates for new categories. Since several partitioning may arise, statistical analysis techniques will be applied to rank the most promising alternatives and present them to the user who will decide which subcategories to add to the catalogue. The techniques proposed by [Maarek 96] could be applied, but to the context path rather than to the content of the documents, in order to produce possible grouping of documents into subcategories.
The concept hierarchy of WordNet could also provide suggestions of possible subcategories.
We propose to extend the Arianna data base to retain the Context Paths produced by the classifier, the estimate records and the classification information for each URL. Exploiting the classification information it will be possible:
We described an approach to the automatic categorisation of documents which exploits contextual information extracted from the HTML structure of Web documents. The preliminary results of our experiments with a prototype categorisation tool are quite encouraging. We expect that incorporating further linguistic knowledge in the tool and exploiting information from a large number of sources, we can achieve effective and accurate automatic classification of Web documents.
We thank Antonio Converti, Domenico Dato, Antonio Gullì, Luigi Madella, for their support and help with Arianna and other tools.
This work has been partly funded by the European
Union, project TELEMATICS LE4-8303 EUROsearch.
We gratefully acknowledge support by the
HP philanthropy program.
[Altavista] AltaVista, http://altavista.digital.com
[Arianna] Arianna, http://arianna.it
[Fuhr 91] N. Fuhr and C. Buckley, A Probabilistic
Approach for Document Indexing, ACM Transactions on Information
Systems, 9(3), 223-248, 1991.
[Lycos] Lycos, http://lycos.com
[Maarek 96] Y.S. Maarek and I.Z.B. Shaul, Automatically
organizing bookmarks per content, Computer Networks and ISDN
Systems 28, 1321-1333, 1996.
[Marais 97] H. Marais and K. Bharat, Supporting cooperative
and personal surfing with a desktop assistant, in Proceedings
of ACM UIST'97, 129-138, ACM, 1997.
[Mathe 97] R.M. Keller, S.R. Wolfe, J.R. Chen, J.L.
Rabinowitz, N. Mathe, A Bookmarking Service for Organizing and
Sharing URLs, Proceedings of the Sixth International WWW Conference,
Santa Clara, CA, 1997. http://ic-www.arc.nasa.gov/ic/projects/aim/papers/www6/paper.html
[Shortliffe 95] G. P. Purcell and E. H. Shortliffe,
Contextual Models of Clinical Publications for Enhancing Retrieval
from Full-Text Databases, Knowledge Systems Laboratory, Medical
Computer Science, KSL-95-48, 1995.
[Shrihari 95] Rohini K. Srihari, Automatic Indexing
and Content-Based Retrieval of Captioned Images, Computer,
IEEE Computer Society; special issue: Finding the Right Image
- Content-Based Image Retrieval Systems, 49-56, 28(9),
1995.
[Weiss 96] Weiss, R., Velez, B., Sheldon, M.A., Nemprempre,
C., Szilagyi, P., Duda, A., and Gifford, D.K., HyPursuit: A Hierarchical
Network Search Engine that Exploits Content-Link Hypertext Clustering,
Proceedings of the Seventh ACM Conference on Hypertext,
Washington, DC, 1996.
[WordNet] G.A. Miller, WordNet: a lexical database
for English, Communications of the ACM, 38(11),
1995, 39 - 41.
[Yahoo] Yahoo!, http://yahoo.com.
Here are candidate paths for the URL http://muse.bio.cornell.edu:
REFERENCES
APPENDIX I FURTHER EXAMPLES OF CLASSIFICATION
science .........................................
1.0
The grading of candidates for http://muse.bio.cornell.edu:
science : general ...............................
1.0 0.0
science : earth .................................
1.0 0.0
science : environment ...........................
1.0 0.0
science : psychology ............................
1.0 0.0
science : mathematics ...........................
1.0 0.0
science : engineering ...........................
1.0 0.0
science : physics ...............................
1.0 0.0
science : chemistry .............................
1.0 0.0
science : space .................................
1.0 0.0
science : astronomy .............................
1.0 0.0
science : computer ..............................
1.0 0.0
science : biology ...............................
1.0 1.0
science : botany ................................
1.0 0.0
technology : biology ............................
0.0 1.0
science : archaeology ...........................
1.0 0.0
science : agriculture ...........................
1.0 0.0
science .........................................
1.0
Here are candidate paths for the URL http://gc.bcm.tmc.edu:8088/bio/bio_home.html:
science : general ...............................
0.5
science : earth .................................
0.5
science : environment ...........................
0.5
science : psychology ............................
0.5
science : mathematics ...........................
0.5
science : engineering ...........................
0.5
science : physics ...............................
0.5
science : chemistry .............................
0.5
science : space .................................
0.5
science : astronomy .............................
0.5
science : computer ..............................
0.5
science : biology ...............................
1.0
science : botany ................................
0.5
technology : biology ............................
0.5
science : archaeology ...........................
0.5
science : agriculture ...........................
0.5
commercial service : library
.................... 0.0 0.0 0.6309298
The grading of candidates for http://gc.bcm.tmc.edu:8088/bio/bio_home.html:
science .........................................
1.0
science : general ...............................
1.0 0.0
science : earth .................................
1.0 0.0
science : environment ...........................
1.0 0.0
science : psychology ............................
1.0 0.0
science : mathematics ...........................
1.0 0.0
science : engineering ...........................
1.0 0.0
science : physics ...............................
1.0 0.0
science : chemistry .............................
1.0 0.0
science : space .................................
1.0 0.0
science : astronomy .............................
1.0 0.0
science : computer ..............................
1.0 0.0
science : biology ...............................
1.0 1.6309298
science : botany ................................
1.0 0.0
technology : biology ............................
0.0 1.6309298
science : archeology ............................
1.0 0.0
science : agriculture ...........................
1.0 0.0
commercial service : library
.................... 0.21030994
Here are candidate paths for the URL http://www.molbiol.ox.ac.uk/www/ewan/palette.html:
science .........................................
1.0
science : general ...............................
0.5
science : earth .................................
0.5
science : environment ...........................
0.5
science : psychology ............................
0.5
science : mathematics ...........................
0.5
science : engineering ...........................
0.5
science : physics ...............................
0.5
science : chemistry .............................
0.5
science : space .................................
0.5
science : astronomy .............................
0.5
science : computer ..............................
0.5
science : biology ...............................
1.315465
science : botany ................................
0.5
technology : biology ............................
0.8154649
science : archaeology ...........................
0.5
science : agriculture ...........................
0.5
commercial service : engine
..................... 0.0 0.0 0.6309298
The grading of candidates for http://www.molbiol.ox.ac.uk/www/ewan/palette.html:
science .........................................
1.0
science : general ...............................
1.0 0.0
science : earth .................................
1.0 0.0
science : environment ...........................
1.0 0.0
science : psychology ............................
1.0 0.0
science : mathematics ...........................
1.0 0.0
science : engineering ...........................
1.0 0.0
science : physics ...............................
1.0 0.0
science : chemistry .............................
1.0 0.0
science : space .................................
1.0 0.0
science : astronomy .............................
1.0 0.0
science : computer ..............................
1.0 0.0
science : biology ...............................
1.0 1.0
science : botany ................................
1.0 0.0
technology : biology ............................
0.0 1.0
science : archaeology ...........................
1.0 0.0
science : agriculture ...........................
1.0 0.0
commercial service : engine
..................... 0.21030994
Here are the result for the categorisation of page
http://www.yahoo.com/Regional/Countries/Italy/Recreation_and_Sports/Sports/Soccer/Clubs_and_Teams/National_Team
science .........................................
1.0
science : general ...............................
0.5
science : earth .................................
0.5
science : environment ...........................
0.5
science : psychology ............................
0.5
science : mathematics ...........................
0.5
science : engineering ...........................
0.5
science : physics ...............................
0.5
science : chemistry .............................
0.5
science : space .................................
0.5
science : astronomy .............................
0.5
science : computer ..............................
0.5
science : biology ...............................
1.0
science : botany ................................
0.5
technology : biology ............................
0.5
science : archaeology ...........................
0.5
science : agriculture ...........................
0.5
Here are candidate paths for the URL http://espn.sportszone.com/soccer/worldcup98/italyindex.html:
politics : national .............................
0.0 1.0
The grading of candidates for http://espn.sportszone.com/soccer/worldcup98/italyindex.html:
public administration : national
................ 0.0 0.0 1.0
sport ...........................................
2.0
sport : individual ..............................
2.0 0.0
sport : team ....................................
2.0 4.0
sport : club ....................................
2.0 1.0
sport : event ...................................
2.0 0.0
sport : news ....................................
2.0 0.0
politics : national .............................
0.5
Here are candidate paths for the URL http://www.france98.com/english/teams/teambio154.htm:
public administration : national
................ 0.33333334
sport ...........................................
2.0
sport : individual ..............................
1.0
sport : team ....................................
3.0
sport : club ....................................
1.5
sport : event ...................................
1.0
sport : news ....................................
1.0
politics : national .............................
0.0 1.0
The grading of candidates for http://www.france98.com/english/teams/teambio154.htm:
public administration : national
................ 0.0 0.0 1.0
sport ...........................................
2.0
sport : individual ..............................
2.0 0.0
sport : team ....................................
2.0 4.0
sport : club ....................................
2.0 1.0
sport : event ...................................
2.0 0.0
sport : news ....................................
2.0 0.0
politics : national .............................
0.5
Here are candidate paths for the URL http://www.soccernet.com/u/soccer/worldcup98:
public administration : national
................ 0.33333334
sport ...........................................
2.0
sport : individual ..............................
1.0
sport : team ....................................
3.0
sport : club ....................................
1.5
sport : event ...................................
1.0
sport : news ....................................
1.0
politics : national .............................
0.0 1.0
The grading of candidates for http://espn.sportszone.com/soccer/worldcup98/italyindex.html:
public administration : national
................ 0.0 0.0 1.0
sport ...........................................
2.0
sport : individual ..............................
2.0 0.0
sport : team ....................................
2.0 4.0
sport : club ....................................
2.0 1.0
sport : event ...................................
2.0 0.0
sport : news ....................................
2.0 0.0
politics : national .............................
0.5
Here are the result for the categorisation of page
http://www.yahoo.com/Regional/Countries/Italy/Re
creation_and_Sports/Sports/Soccer.
public administration : national
................ 0.33333334
sport ...........................................
2.0
sport : individual ..............................
1.0
sport : team ....................................
3.0
sport : club ....................................
1.5
sport : event ...................................
1.0
sport : news ....................................
1.0
Here are candidate paths for the URL http://www.arpnet.it/~aia:
sport ...........................................
2.0
The grading of candidates for http://www.arpnet.it/~aia:
sport : individual ..............................
2.0 0.0
sport : team ....................................
2.0 0.0
sport : club ....................................
2.0 0.0
sport : event ...................................
2.0 0.0
sport : news ....................................
2.0 0.0
sport ...........................................
2.0
Here are candidate paths for the URL http://www.dossier.net:
sport : individual ..............................
1.0
sport : team ....................................
1.0
sport : club ....................................
1.0
sport : event ...................................
1.0
sport : news ....................................
1.0
sport ...........................................
2.0
The grading of candidates for http://www.dossier.net:
sport : individual ..............................
2.0 0.0
sport : team ....................................
2.0 1.7618597
sport : club ....................................
2.0 0.0
sport : event ...................................
2.0 0.0
sport : news ....................................
2.0 0.0
sport ...........................................
2.0
Here are candidate paths for the URL http://www.mclink.it/com/ies/calcio:
sport : individual ..............................
1.0
sport : team ....................................
1.8809298
sport : club ....................................
1.0
sport : event ...................................
1.0
sport : news ....................................
1.0
sport ...........................................
2.0
The grading of candidates for http://www.mclink.it/com/ies/calcio:
sport : individual ..............................
2.0 0.0
sport : team ....................................
2.0 0.0
sport : club ....................................
2.0 0.0
sport : event ...................................
2.0 0.0
sport : news ....................................
2.0 0.0
sport ...........................................
2.0
Here are candidate paths for the URL http://web.tin.it/raitgs/mcalcio/msoccer.htm:
sport : individual ..............................
1.0
sport : team ....................................
1.0
sport : club ....................................
1.0
sport : event ...................................
1.0
sport : news ....................................
1.0
sport ...........................................
2.0
The grading of candidates for http://web.tin.it/raitgs/mcalcio/msoccer.htm:
sport : individual ..............................
2.0 0.0
sport : team ....................................
2.0 0.0
sport : club ....................................
2.0 0.0
sport : event ...................................
2.0 0.0
sport : news ....................................
2.0 0.0
sport ...........................................
2.0
sport : individual ..............................
1.0
sport : team ....................................
1.0
sport : club ....................................
1.0
sport : event ...................................
1.0
sport : news ....................................
1.0