Theseus: Categorization by Context
Giuseppe Attardi
Dipartimento di Informatica, Università di Pisa, Italy
attardi@di.unipi.it
Antonio Gullì
Studio I-Tech, Pisa, Italy
Fabrizio Sebastiani
Istituto di Elaborazione dell’Informazione, Pisa, Italy
fabrizio@iei.pi.cnr.it.it
Abstract:
Assistance in retrieving of documents on the World Wide Web is provided either by search engines, through keyword based queries, or by catalogues, which organize documents into hierarchical collections. Maintaining catalogues manually is becoming increasingly difficult due to the sheer amount of material on the Web, and therefore it will be soon necessary to resort to techniques for automatic classification of documents. Classification is traditionally performed by extracting information for indexing a document from the document itself. The paper describes the novel technique of categorization by context, which exploits the context where an URL appears, to extract useful information for classifying the document referred by the URL. The context is inferred from the structure of HTML documents. We present the results of experiments with Theseus, a classifier that exploits the technique.Key Words: information retrieval, Web search, text categorization, hypertext navigation
Categories: H.3.1, H.3.3, H.3.5, H.5.1, I.2.7, I.5.3
Assistance in retrieving documents on the Web is provided by two kinds of tools: search engines and classified directories.
Search engines provide keyword-based search on the content of quite large collections of Web documents. The results of a query are displayed as a linear list of documents, typically ranked in order of relevance. Unfortunately the list is often quite long and users have neither the willingness nor the skills necessary to perform complex boolean queries to narrow the search: a recent survey shows that the average query contains less than 3 keywords and that boolean queries are rarely used [Jansen 98]. Since the Web contains material of quite different varieties, users cannot anticipate what is available, find difficult to express their interests and get surprising results because of word ambiguities.
Classified directories organize a usually smaller subset of Web material in catalogues, consisting in a hierarchy of thematic categories: each category lists Web pages (or sites) deemed relevant for that category. Altavista™ [Altavista], Hotbot™ [Hotbot], Infoseek™ [Infoseek] are among the foremost general search engines, while Inktomi™ [Intomi] and Excite™ [Excite] specialize in providing search technology for search services in restricted domains. Lycos™ [Lycos] and Yahoo!™ [Yahoo] are among the most well known Web directories. A recent trend is visible toward the integration of the two kinds of services: Altavista™ [Altavista] has added a catalogue-based service, Lycos plans to merge its services through its acquisition of HotBot. Northern Light [Northern Light] provides an interesting combination in their search service, which dynamically organizes the results of a keyword search into groups with similar subject, source or type.
Users have shown to appreciate the value of catalogues. By navigating in a catalogue and docking to the category c of interest, a user may either (a) directly access relevant sites pre-categorized under c, or (b) perform keyword-based searches restricted to the documents within c.
The value of a catalogue can be expressed in terms of the quality of its classification schema (how understandable, accepted, complete, ordered and synthetic it is), authoritativeness (the degree of user confidence on the catalogue), accuracy (how proper is the assignment of a document to a category), consistency (similar documents are classified in the same way), timeliness (how quickly it reflects changes in the document collection), completeness (the presence of all relevant documents in each category), selectivity (the quality of listed material). The last two aspects are conflicting, since sometimes a more selective catalogue, one which chooses to exclude some material of lower quality may be preferable to a more complete listing.
Achieving these qualities in a catalogue is a difficult task. Deciding whether a document d should be categorized under category c requires, to some extent, an understanding of the meaning of both d and c. Because of this, categorization has traditionally been accomplished manually, by trained human classifiers. This is clearly unsatisfactory since:
Techniques for automatic classification of Web pages are starting to be exploited on large scale: beyond the already mentioned Northern Light, Lycos and Arianna [ACAB] have recently made available online automatically built portions of their catalogue; Inktomi uses automatic classification in building sites like the Disney Internet Guide.
Automatic classification is typically performed by comparing representations of documents with representations of categories and computing a measure of their similarity. In many cases category profiles are built by specialist librarians [Northern Light] combining information from several sources (general classification indexes, specialized thesauri, etc.).
Techniques for automatically deriving representation of categories ("category profile extraction") and performing classification have been developed within the area of text categorization [Ittner 95, Lewis 96, Yang 94, Yang 97], a discipline at the crossroads between information retrieval and machine learning. Text categorization uses machine learning techniques to inductively build, from a training set of documents pre-categorized according to a given classification, a representation of categories which an automatic process (classifier) can compare with the representation of a document in order to decide to which categories it belongs.
Alternatively, a document can be compared to previously classified documents and placed in the category of the closest such documents [Fuhr 91], avoiding the need for category profiles.
The representation of documents is obtained through standard indexing techniques developed within the field of information retrieval [Salton 88]. Vector space retrieval [Salton 75] and fuzzy retrieval [Bookstein 76] are measures of similarity used to perform categorization.
Approaches based on identification of concepts have also been proposed which exploit neural network techniques [Autonomy] or linguistic and semantic analysis [InQuizit].
Several new techniques are being proposed specifically for the context of Web [Kleinberg 97, Brin 98].
All the approaches to categorization mentioned so far perform categorization by content [Yang 94, Schütze 95, Ng 97], since information for categorizing a document is extracted from the document itself.
Categorization by content does not exploit an essential aspect of a hypertext environment like the Web, namely the structure of documents and the link topology.
In this paper we investigate a novel technique for automatic categorization, which we dubbed categorization by context, since it exploits the context surrounding a link in an HTML document to extract useful information for categorizing the document referred by the link. Categorization by context exploits relevance hints that are present in the structure and topology of the HTML documents published on the Web. Combining a large number of such hints, an adequate degree of accuracy of classification can be achieved.
Context-based indexing categorization has the significant advantage that it can deal also with multimedia material, including images, audio and video [Shrihari 95, Guglielmo 96, Harmandas 97], since it does not rely on the ability to analyze the content of documents to classify.
Categorization by context leverages on the categorization activity that users implicitly perform when they place or refer documents on the Web, turning categorization, form an activity delegated to a restricted number of specialists, into a collaborative effort of a community of users. By restricting the analysis to the documents used by a group of people, one can build a categorization that is tuned to the need of that group.
In this paper we report on our experience in building Theseus [Teseo], an automatic classifier of Web documents that exploits the context of links in Web documents [Attardi 98].
Several approaches have been attempted for improving the services provided by Web search engines.
Altavista provides a refine capability, whereby users receive suggestions about terms to include or exclude for refining the query. The problem with this approach is that suggested terms are only statistically related to query terms and rarely represent useful semantic concepts. The refined query narrows the focus of search, but does not direct the search toward the topic of interest. Moreover the approach puts additional burden on the user while providing limited benefits.
Infoseek provides grouping of query results and also allows retrieving pages similar to a given one. Related pages take the user to a parallel, possibly overlapping set of classified documents, but not necessarily to more focused ones.
Northern Light has introduced the technique of Custom Search FoldersÔ . Results of traditional keyword searches are dynamically organized into folders containing documents with similar subjects, sources, or types. When a folder is opened, a new subset of the original result list is produced containing more focused results. To implement the service, Northern Light pre-classifies automatically its whole collection of documents according to: (a) subject, using a subject hierarchy of 20000 terms hand crafted by human specialists, (b) type, in a shallow hierarchy of 150 document types, (c) language, (c) source (collection, Home Page, educational site, etc.). By performing the classification in advance, the grouping of query results can be produced quickly and effectively.
Custom Search Folders are dynamically created, as opposed to the static structure of a manually built catalogue like Yahoo!.
As an example of the benefits of this approach, consider a query on "citation processing". A typical search engine will produce several million of results, whose topics include driving violation, information retrieval, data processing, etc. With Infoseek, one can select among the results for instance a journal on information retrieval and ask for related pages; however this produces a list of 6 times more pages, apparently drifting into documents unrelated to the original query. Northern Light produces instead a number of search folders, including: Probation, Government sites, Archive & record management, Document management, Office equipment, Information retrieval. Within the latter folder, one finds folders about: Clustering, Relevancy ranking, and bubl.ac.uk (the site of the journal Information Processing and Management), that indeed help in discriminating among documents.
Automatic categorization techniques may lead to better Web retrieval tools that provide access to large amount of up-to-date documents, like search engines, with the convenience of selecting among properly organized material, like in classified directories.
Lycos is now providing a catalogue built through automatic classification: however the new catalogue consists only of links, with no summary or other useful information regarding the contents of sites. Lycos uses relevance feedback from users and sorts each list of recommended Web sites accordingly.
ACAB [ACAB] uses automatic classification techniques based on matching hand-crafted category profiles with the contents of documents and also builds an automatic summary of page contents which is displayed in the catalogue.
Categorization by context is a technique for automatic categorization based on the following hypotheses:
Indeed a document would never be visited, except in casual browsing or through a direct referral, unless there are perceivable clues of its possible interest to potential readers. When people browse through documents, they base their decisions to follow a link on its textual description or on its position (in case of image maps or buttons). At least for textual links, in principle a document should provide sufficient information to describe a document it refers to. HTML style guides [Tilton 95] suggest making sure that the text in a link is meaningful, avoiding common mistakes like using adverbs or pronouns: "The source code is here" or "Click this". Even if the link itself is not sufficiently descriptive, the surrounding text or other parts of the document normally supply enough descriptive information. If such information is sufficient to decide whether a document is worth reading, we can assume it is also sufficient to categorize a document.
The classification task must then be capable of identifying such hints. One obvious hint is just the anchor text for the link (the text between tags <A> and </A>). But additional hints may be present elsewhere in a page: page title, section titles, list descriptions, etc. Our idea is to exploit the structure of HTML documents to extract such hints. Moreover, a page may have been reached from some other page, whose context as well may be relevant, although to a lesser extent.
Categorization by context exploits both the structure of Web documents and Web link topology to determine the context of a link. Such context is then used to classify the document referred by the link.
One may think that instead of classifying a document, we classify a virtual document, made up of portions of other documents that refer to it. The advantage of this approach is that typically one refers to a document with a more concise description and more pregnant terms than those in the document, as in the case of third party reviews. This simplifies categorization since the presence of terms, which mislead the classifier, is less likely.
Hypertext links pointing to the document to be categorized have not been used so far for categorization, although they have been used as clues for searching documents [Chalmers 98, Li 98], and for measuring the "importance" of a Web site [Brin 98].
Contextual information is exploited in ARC [Chakrabarti 98], a system for automatically compiling a list of authoritative Web resources on a topic, further discussed in Section 10.
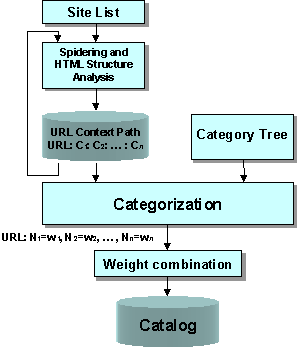
The technique of categorization by context consists in extracting contextual information about documents by analyzing the structure of Web documents that refer to them. The overall architecture of the task of categorization by context is described in [Fig. 1], and consists in spidering Web documents, HTML structure analysis, URL categorization, weight combination and catalogue update.
This task starts from list of URLs, retrieves each document, analyzes the structure of the document expressed in terms of its HTML tags. For an introduction to HTML we refer to the HTML Primer [HTML].
The tags considered are currently: <TITLE>, <Hn>, <UL>, <DL>, <OL>, <A>. Whenever one of these tags is found, a context phrase is recorded, which consists of the title within a pair <Hn> </Hn>, or the first portion of text after a <UL> or <DL> tag, or the phrase within a <A> tag. When a <A> tag is found containing an URL, an URL Context Path (URL: C1: C2: … : Cn) is produced, which consists of the sequence of the context strings so far (C1: C2: … : Cn) associated to the URL. Therefore C1 is the text in the anchor of the URL, and the other Ci are the enclosing contexts in nesting order.
In the analysis tags related to layout or emphasis (<EM>, <B>, <CENTER>, <FONT> etc.) are discarded.
Another possible element for a context is the title of a column or row in a table: tag <TH>. Such title can be effectively used as a context for the elements in the corresponding column or row.
Figure 1: Architecture of Categorization by Context
We will use throughout the following example, consisting of a fragment of an HTML page from Yahoo™! (http://www.yahoo.com/Science/Biology):
The HTML source for this page is:
<html>
<head>
<title>Yahoo! - Science:Biology</title>
</head>
<body>
…
<ul>
<li>
<a href="http://esg-www.mit.edu:8001/esgbio/">
M.I.T. Biology Hypertextbook</a> - introductory resource including information on chemistry, biochemistry, genetics, cell and molecular biology, and immunology.
<li>
<a href="http://muse.bio.cornell.edu/">
Biodiversity and Biological Collections</a>
- information about specimens in biological collections, taxonomic authority files, directories of biologists, reports by various standards bodies, and more.
<li>
<a href="http://gc.bcm.tmc.edu:8088/bio/bio_home.html">
Biologist’s Control Panel</a> - many biology databases, library and literature links.
<li>
<a href="http://www.molbiol.ox.ac.uk/www/ewan/palette.html">
Biologists Search Palette</a> - a collection of useful search engines for biological databases on the Internet, accessed through either the Web or gopher.
…
</body>
</html>
the following context paths are created:
http://esg-www.mit.edu:8001/esgbio:
"M.I.T. Biology Hypertextbook" :
"introductory resource including information on chemistry, biochemistry, genetics, cell and molecular biology, and immunology" :
"Yahoo! - Science:Biology"
http://muse.bio.cornell.edu:
"Biodiversity and Biological Collections"
"information about specimens in biological collections, taxonomic authority files, directories of biologists, reports by various standards bodies, and more"
"Yahoo! - Science:Biology" :
"http://gc.bcm.tmc.edu:8088/bio/bio_home.html"
"Biologist’s Control Panel"
"many biology databases, library and literature links"
"Yahoo! - Science:Biology" :
"http://www.molbiol.ox.ac.uk/www/ewan/palette.html"
"Biologists Search Palette"
"a collection of useful search engines for biological databases on the Internet, accessed through either the Web or gopher"
"Yahoo! - Science:Biology" :
Any URL found during the analysis is passed back to the spidering process, if it points to a document within the current site and stored for later analysis if it points to an external site. This allows us to perform a depth-first visit of a site, collecting any categorization information it contains about itself and other sites.
The categorization task exploits the database of URL Context Path and the Category Tree within which the URL must be categorized. The Category Tree consists of a tree (or a DAG), where each node contains a title, i.e. a single word or phrase, which identifies the category.
The goal of the categorization is to find the most appropriate categories to which an URL should belong. The output of the categorization is a sequence of weights associated to each node in the Category Tree:
URL: N1=w1, N2=w2, … , Nn=wn
Each weight wi represents a degree of confidence that the URL should belong to the category represented by node Ni.
The weights from the Context Path for a URL are added with all other Context Paths for the same URL and normalized. If the weight for a node is greater than a certain threshold, the URL is categorized under that node.
The mechanism should allow for categorizing an URL under more than one node, but never in two nodes which are descendant of one another.
The categorization algorithm represents each node in the Category Tree as a path. For instance, let us consider the Arianna [Arianna] search engine for the Italian Web space that we are using for our experiments, and the following part of the Arianna category tree (translated into English):
Business
Insurance
Banks
Events and Fairs
News
Companies
Publications
Schools
Computer
Distribution and Sale
Events and Fairs
Publications
Schools
Software and Hardware
Sport
Events
News
This tree corresponds to the following paths:
Business: Insurance
Business: Banks
Business: Events
Business: Fairs
Business: News
Business: Companies
Business: Publications
Business: Schools
Computer: Sale
Computer: Distribution
Computer: Events
Computer: Fairs
Computer: Schools
Computer: Software
Computer: Hardware
Sport: Events
Sport: News
Notice that some categories (e.g Events) appear in several places, therefore the title of the category is not sufficient to identify the category: the whole path is necessary to disambiguate among the categories. Categorization by context exploits this fact in a fundamental way to resolve ambiguities: the presence of terms which match a category fades to irrelevance unless there are other matches with all categories in the path which confirm the specific meaning of the term. For instance, the term "band" may refer to a musical group or to clothing. The term will not contribute to categorization unless the context contains some other word that matches with either Music or Fashion, and all other categories up to the top-level of the catalogue.
Notice also that we split into two paths any title that contains two terms joined by "and": the original category corresponds to the union of the two paths.
The categorization algorithm works as follows: for categorizing an URL it computes first a vector of matching weights for each path in the Category Tree, then it determines the paths with the best matching vectors. Once all URL have been categorized, a catalogue is built by assigning each URL to the best matching categories.
Given an URL context path (URL: C1: C2: … : Cn), the algorithm considers in turn each Ci, starting from C1. To each level we associate a weight dl, decreasing from C1 = 1, for instance with a value 1/log2(l + 1). It may be worthwhile to adapt these weights take into account the significance of a tag, for instance a <TITLE> tag may have a slightly higher weight than its position would imply.
Then we extract from Cl the noun phrases it contains n0, … , nk, as described in [Section 6.2].
For each path p in the Category Tree, we create a path match vector pv with as many fields as the path length, initialized to 0.
Each phrase ni is matched against each title in each path. If there is a match between ni and the title of category in the k-th position in path p, with matching weight mw, then dl ´ mw is added to pvk. This process is repeated for each level 1 < l < n.
Notice that since there can be several matching, the value in a field of a path match vector can be greater than one; therefore these values are normalized before performing comparisons.
For example, here are the non zero vectors for the URL http://esg-www.mit.edu:8001/esgbio in our example. On the left we display the path and on the right the corresponding match weight vector, which has an entry for each element of the path representing the weight of the match for the corresponding title.
science ......................................... 1.0
science : general ............................... 1.0 0.0
science : earth ................................. 1.0 0.0
science : environment ........................... 1.0 0.0
science : psychology ............................ 1.0 0.0
science : mathematics ........................... 1.0 0.0
science : engineering ........................... 1.0 0.0
science : physics ............................... 1.0 0.0
science : chemistry ............................. 1.0 0.0
science : space ................................. 1.0 0.0
science : astronomy ............................. 1.0 0.0
science : computer .............................. 1.0 0.0
science : biology ............................... 1.0 2.13093
science : botany ................................ 1.0 0.0
technology : biology ............................ 0.0 2.13093
science : archaeology ........................... 1.0 0.0
science : agriculture ........................... 1.0 0.0
Path match vectors have a quite different meaning from the index vectors used in text based information retrieval. For instance in the knn method for information retrieval, n keywords are used to represent documents, and a vector v of n elements is associated to a document; vi is and indication of the occurrence of the i-th keyword in the document, typically based on tf (term frequency) and idf (inverse document frequency). Index vectors are directly compared among themselves or with index vectors for categories. The path match vector for a document may be considered as consisting of elements of the form:
pvi = c ∙ v
where c is the index vector for the i-th category (category profile) and v is the index vector for the document.
Any path match vector pv that contains non-zero fields is considered as a potential candidate. The selection among these candidates is performed as follows:
The first criterion is essential since it provides categorization by context with the ability to disambiguate between senses of words: only the sense which is confirmed by the context for all the categories up to the top of the classification hierarchy is retained.
The selected estimate records are stored in the database, associated to the URL. When the same URL is reached form a different path, the new estimates are combined to the previous ones. This will either enforce the indication of the category for a URL or suggest alternative categories for the URL.
The grading of candidates for http://esg-www.mit.edu:8001/esgbio produces the following:
science ......................................... 1.0
science : general ............................... 0.5
science : earth ................................. 0.5
science : environment ........................... 0.5
science : psychology ............................ 0.5
science : mathematics ........................... 0.5
science : engineering ........................... 0.5
science : physics ............................... 0.5
science : chemistry ............................. 0.5
science : space ................................. 0.5
science : astronomy ............................. 0.5
science : computer .............................. 0.5
science : biology ............................... 1.565465
science : botany ................................ 0.5
technology : biology ............................ 1.065465
science : archaeology ........................... 0.5
science : agriculture ........................... 0.5
In order to compute the match between a noun phrase in a context and a title in the catalogue, we exploit several tools and data structures.
First, since it is likely that noun phrases do not use the exact terms present in the titles, we must widen somewhat the search. In order to do this we precompute a neighborhood of words for each term in a title, exploiting information from WordNet [Miller 95], which we store in a neighborhood table. Second, matching a noun phrase with a title, which in general is also a noun phrase, requires matching multiple words.
In the following we will denote with D the set of titles of categories in the Categorization Tree, and with DS the set of single words in D.
For each term t in DS we build the set I(t) of terms in the neighborhood of t (synonyms, hyponyms, etc.). Moreover, for each term s in I(t) we denote with w(s, t) the weight of s with respect to t, which expresses how closely s is related term to t. If a term belongs to several of these classes, w(s, t) takes the largest of such weights.
We implement the inverted list of I as a hash table TI whose keys are elements in DS. Since we need to know the matching weight of each pair of words, it is convenient to store in this table not just the matching word but also the matching weight. Therefore the table associates to each word s in the neighborhood of some term t, a set of pairs
Table TI can be built as follows:
Example:
Let ‘sport event’ be the title of one category, then sport event is in D, sport and event are in DS. Table I might look like this:
|
word |
neighborhood |
|
sport |
{football, basketball, tennis, … } |
While table TI could be like this:
|
word |
related title words |
|
sport … |
{‹sport, 1.0›, … } |
Before matching a context with category titles, we extract from the context the noun phrases it contains. For this task we currently use TreeTagger [Schmid 94], a lexicon-based part of speech (POS) tagger with a stochastic disambiguator. For example, when TreeTagger analyzes the sentence
The World Wide Web has become an impressive open structure for sharing information
it returns the tag and the lemma for each word, shown here on separate lines:
The World Wide Web has become an impressive open structure for sharing information
DT NP NP NN VBZ VBN DT JJ JJ NN IN VBG NN
the world wide web has become a impressive open structure for share information
From such series we consider sequences of adjectives and nouns which form noun phrases, obtaining:
World Wide Web
impressive open structure
information
The example shows that tagging avoids the mistake of considering the term World in itself, which would lead to inappropriate categories, but rather suggests to consider it as part of a phrase whose main subject is Web.
A POS tagger is essential here, since the lexical information provided by WordNet is not sufficient to determine the proper meaning and role of a word in the context of a phrase.
The next step is matching a noun phrase from a context with the category titles from the catalogue. For instance we might have the noun phrase football match which should match with the title sport event.
Let s = s0 … sn be a noun phrase consisting of a sequence of words si. We must find a category title t = t0 … tn where each si Î I(ti) and to retrieve the corresponding weights w(si, ti).
We can construct all possible sequences:
t0 … tn
exploiting the information in table TI, substituting each si with any ti such that ‹ti, w(si, ti)› Î TI(si). In order to determine quickly whether a sequence corresponds to a title and in which position in the path the title appears, we use a hash table which associates noun phrases to pairs of a path match vector and the corresponding index. There can be more than one pair since the same title may appear in more than one place in the category tree.
If no match is found, the process is repeated with s = s1 … sn and so on. The reason for this is that a noun phrase may be over specific, for instance because of the presence of too many adjectives. By dropping such adjectives, we generalise the phrase and try to match it again.
Having found the weights w(si, ti) for a phrase, there are several ways to combine them to form the overall weight of the match between the noun phrase and the category title. We chose to use the average of w(si, ti) for all i. Such value mw is added to the weight vector of each path which contains the title, as described in [Section 4.1].
Theseus is a tool for categorization by context has been built in order to verify the validity of the method. Theseus works currently for English and Italian using a language independent part-of-speech tagger [Schmid 94], for which are available English, Italian, French and German lexicons.
An HTML structure analyzer has been built in Java. It builds a context tree for each HTML page analyzing the parse tree produced by an HTML parser written in Perl.
The spidering program is written in Java™ and uses the HTML analyzer to produce a database of URL Context Paths.
Also in Java™, we developed a categorizer program that interfaces to TreeTagger [Schmid 94] to perform lexical analysis of the sentences appearing in the context paths. TreeTagger performs part-of-speech tagging and morphing and returns the lemmas for the words in each sentence.
Spidering and categorization are performed exploiting a transaction system: each operation is recorded in a persistent storage, so that it can be resumed if there is a failure anywhere, for instance in the connection or because the program is interrupted. The transactional data base is implemented by interfacing through Java Native Invocation to the GNU gdbm data base system.
We have used the Arianna [Arianna] catalogue for the experiment, and built catalogues from both English and Italian collections of Web pages.
The benefits of linguistic analysis in information retrieval have always been controversial. In order to determine whether performing noun phrase analysis improves the precision of classification, we compared the classifier with a version that does not perform analysis of noun phrases from contexts. The following table shows the resulting overall difference in the number of entries placed in the top-level categories of the two catalogues:
|
Category |
Without |
With |
|
scuola e istruzione |
955 |
971 |
|
salute |
288 |
311 |
|
sport |
765 |
731 |
|
informazione e notizia |
322 |
327 |
|
organizzazione sociale |
1 |
1 |
|
politica e società |
2440 |
2550 |
|
arte e cultura |
1093 |
1084 |
|
intrattenimento |
650 |
628 |
|
viaggio e turismo |
695 |
683 |
|
computer, internet e telecomunicazioni |
602 |
576 |
|
economia |
1518 |
1462 |
|
tempo libero |
172 |
184 |
In fact most of the differences arise from differences in the analysis of noun phrases.
For example, the sentence "interno dell'omonimo liceo" ("inside the high school with the same name") misleads the classifier to place an entry within the category "liceo" (high school), and similarly for "studentessa di liceo" ("a high school female student"). In fact both sentences contain the word "liceo" but as an indirect reference. Noun phrase analysis in both cases detects that the subject of the phrase is not "liceo" ("high school") and so it avoids giving a high weight to the occurrence of such term.
Overall in this experiment, there was an improvement of approximately 5% in precision by performing noun phrase analysis.
Quite often the pages of a site have a characteristic structure represented by links across pages. For instance there can be references to the main page, or links to the general services available in the site, like searching within the site, help or information pages. Finally there can be advertisement banners in precise position s in each page. We want to avoid classifying such pages. In order to identify these structural links, we perform an initial breadth first analysis of pages reachable from the starting page, currently limited to a depth of 3. Any links which are repreated at a frequency above 90% of the overall number of visited pages is considered a structural link, placed in a stop list of URLs and discarded in the subsequent analysis of the site.
Sometimes links are embedded within CGI references, e.g. HREF="/cgi/go?http://www.inrete.it/classica". This technique is used by site administrators to keep track of the links that users select from their pages. This can be useful for several purposes: determining which pages are more interesting to users, measuring the number of pages referrals toward other sites (particularly important for advertisers’ sites), reordering the content of a page by placing the most requested URLs in more prominent position, etc. Identification of such embedded links is performed by Theseus in the initial phase of site analysis. If a repeated pattern containing URLs in the HREF fields is detected, the URLs themselves are stripped from such pattern.
Site border identification is essential since we consider documents to be classified any URL which lays outside the border of the current site. A first approximation is to consider external any URL that has a different prefix. Sometimes however this is not sufficient and we might have to perform iterative analysis of link topology, like in [Chakrabarti 98], in order to identify such borders.
There are several benefits in performing the classification in close integration with a search engine. The most obvious one is to avoid a separate spidering of Web documents. The spidering performed by the search engine can be used also by the classifier, which is passed any new document discovered by the spider.
We also plan to exploit the Arianna search engine in the identification of initial sites for the categorization. An HTML page can be considered as a suitable source for categorization if it contains a large number of links to external pages. In the terminology of [Chakrabarti 98] these are called hubs. From the indexing information maintained by Arianna, it is possible to obtain such information just by querying its database. However it is important to select as initial sites pages whose content is authoritative. Therefore the algorithm of ARC should be used to identify authoritative hubs.
The search engine can be exploited also to provide support for queries within categories. It is sufficient to provide the list of documents within each category so that the search engine can index them.
Vice-versa, category information produced by the classifier can be used in the search engine to improve the presentation of query results, grouping them by categories, like in Northern Light.
The results achieved with the current prototype are quite encouraging. In most cases, the prototype was able to categorize each URL in the most appropriate category. The few exceptions appeared due to limitations of the linguistic tools we used for building word neighborhoods: e.g. holes in the WordNet concept tree.
As an experiment to determine the quality of the categorization, we tried to categorize a subset of the Yahoo! pages according to the same Yahoo! catalogue. In principle we should have obtained exactly the original categorization, and this is what we obtained in most cases. In a few cases the algorithm produced an even better categorization, by placing a document in a more specific subcategory: for instance a journal on microbiology was categorized under the subcategory of microbiology journals rather than on the category biology journals where it appeared originally.
Theseus performance is also satisfactory: it classifies approximately 500 sites per hour. Examples of catalogues built using Theseus are available at http://medialab.di.unipi.it/Project/Arianna/Teseo. The largest one lists over 27000 documents and was built in two runs of approximately 4 hours each. Figure 2 shows the main page of such catalogue. For each category, the number of documents within that category or its subcategories is shown.
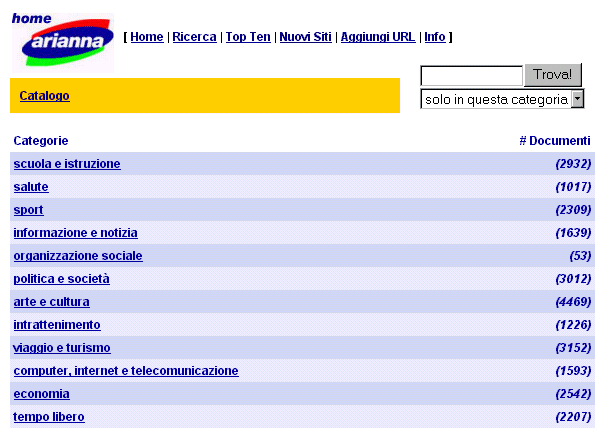
Figure 2. The top page of Theseus’s catalogue.
Figure 3 shows a portion of the catalogue page on search engines. Each entry consists of a rank, a URL, and the closest contexts for the URL (there can be more than one if the document is linked from several pages). The anchor for the URL is also extracted from a context. For purposes of analysis, at the moment we also show the noun phrases that contributed to classifying the document within this category.
We have compared the catalogue built by Theseus with the catalog built by ACAB using categorization by content on the italian Web space. For instance Theseus placed 180 documents in the category Search Engines. ACAB instead found over 500; however many of these where not search engine pages, but pages with links to search engines or which mentioned search engines. In this case Theseus appeared to be more precise. Another difference is that Theseus typically detects the main page of a site or of a compound document, since the main page is more likely to be referred by other documents. On the other hand classification by content cannot easily distinguish between main page and other pages, even though certain heuristics can be applied [ACAB].

Figure 3. A portion of a catalogue page on Search Engines.
The neighborhood table is a critical component of the present implementation. The quality of categorization depends on the quality of neighborhoods.
In our first implementation we relied on WordNet for building such neighborhoods. We extracted for each word in a category title its synonyms, hyponyms and related words. The weights w(s, t) were assigned according to whether t was a synonym, hyponym or a related word with s.
We noticed that the use of related words introduces noise, but on the other hand by discarding them completely we miss some important connections, for instance between "military" and "arm". Therefore we had to give low weights to related words.
For the experiments with Italian documents, we could not use WebNet, since the Italian version is still under construction. A first approximation was to use the English version of neighborhoods and to translate them into Italian. This also proved unsatisfactory and we had to revise them significantly by hand.
The neighborhood of a word is equivalent to a traditional category profile, when the category title contains a single word. However, when a title contains several words, neighborhoods produce some crosstalk. Therefore we are planning to implement category profiles also for multiple words titles.
In building category profiles we have several options, create them by hand, possibly by means of some interactive tools like in ACAB [ACAB], or use learning techniques like those by [Fuhr 91]. The latter technique requires a training set of categorized documents, so it raises problems of bootstrapping. A possible solution is to start with a catalog build with Theseus with minimal category profiles, made just with synonyms of titles. A learning phase could then be applied to such catalogue for extending the category profiles.
An another issue is the proper ranking of documents in the catalogue. Our experience shows that if we start from authoritative sites, the algorithm performs fairly well and produces pages in an acceptable ranking order. The problem arises when we le the classifier crawl freely among sites. We should value differently the contribution to categorization from different sites: we could use the authoritative measure of ARC or the page ranking schema of [Page 98].
Citation processing is any retrieval technique in which documentary citations are traced to identify documents related to a given one. Citation processing techniques are typically used for quantitative analysis, for instance to measure the "impact factor" of scientific journals.
Given two documents d1 and d2, incoming citations are used in computing co-citation strength, i.e. the number of documents that quote both d1 and d2. Outgoing citations are used to compute the bibliographic coupling [Kessler 63], i.e. the number of documents that are quoted by both d1 and d2.
Citation processing is being applied in the context of hypertext information systems [Savoy 97].
The Web provides a new opportunity for citation processing to exploit "citation in context so that quantitative data can be augmented with qualitative statements about the work being cited" [Garfield 97]. This suggests a possible evolution of the techniques of citation processing towards more sophisticated techniques of context link analysis, which exploit not only link topology but also the semantic structure of documents.
Categorization by context is therefore an early application of context link analysis, as well as some other systems, which we review in the following sections.
The ARC system performs automatic resource compilation by using citation processing and limited context analysis [Chakrabarti 98]. Given a topic t, ARC computes for each Web page p two scores: its authority value a(p), which measures how "authoritative" is p with respect to t in terms of the number of t-related pages pointing to it, and its hub value h(p), which measures the "informative content" of p on t in terms of the number of t-related pages it points to. The purpose of ARC is to identify, given a topic t, the k most authoritative and k most informative Web documents. ARC is "kick-started" by issuing query t to AltaVista, which provides an initial set of documents relevant to t; an expansion phase follows, in which documents with distance d £ 2 in the citation graph are added to the set.
The algorithm computes the scores for each page p iteratively. Each iteration consists of two steps: (1) replace each a(p) by the weighted sum of the h(p) values of pages pointing to p; (2) replace each h(p) by the weighted sum of the a(p) values of pages pointed to by p. A weight w(p, q) is assigned to each link (from page p to page q) that increases with the amount of topic-related text in the vicinity of the HTML link from p to q. This weight is computed from the number of matches between terms in the topic description and a window of 50 bytes of text of the href. The topic-related text can be considered contextual information that the algorithm propagates through links reinforcing the belief that a page is an authority on a topic.
The algorithm formalizes the intuition that the hub value of a page is high if the page points to many authoritative pages, and that the authority value of a page is high if many informative pages refer the page.
The authors report that, for k = 15, normally the algorithm near-converges (i.e. the identity of the top 15 authority and hub pages stabilizes) in approximately 5 iterations.
Google [Brin 98] is a search engine, which rates Web pages along a single "authoritativeness" scale. The value P(d) of a given page d is iteratively calculated, until near-convergence. Google avoids spamming by ensuring that a document achieves a highly rank after a query only if it is quoted by many already highly ranked documents.
Google uses several cues other than links for better ranking a document d, such as anchor text, the words that appear in the title and in the text of d, etc.
[Harmandas 97] describes a technique for searching images on the Web based on analyzing the text of documents that point to documents containing images.
Rankdex [Li 98] is a search engine based on standard information retrieval techniques applied to the anchor text of Web links.
Table 1 summarizes the main features and techniques used in the system we discussed.
|
Theseus [Attardi 98] |
ARC [Chakrabarti 98] |
[Brin 98] |
Rankdex [Li 98] |
|
|
Stemming |
yes |
no |
no |
no |
|
Stop word removal |
yes |
no |
optional |
no |
|
Incoming links |
yes |
yes |
yes |
yes |
|
Outgoing links |
no |
yes |
no |
no |
|
Statistical weighting |
yes |
no |
no |
yes |
|
Syntactic analysis |
yes |
no |
no |
no |
|
Lexical resources |
yes |
no |
no |
no |
Table 1. Comparison chart of automatic Web classifiers
The algorithm used by ARC systematically removes from its list of authoritative and (especially) informative pages, those pages belonging to super-hubs, i.e. catalogue-based search engines [Chakrabarti 98a]. The rationale for this is to avoid "parasitical behavior", i.e. to avoid exploiting the contribution of those systems ARC intends to compete with. Although on the surface this looks like safe scientific practice, this decision seems debatable, in that (a) the same scientific practice might as well prevent "parasiting" on AltaVista, and (b) it dwells on the problematic distinction between a hub and a super-hub. More importantly, this decision seems to miss the very point of using context link analysis. These techniques are parasitical by nature, in that they purport to determine the relevance, or authoritativeness, of document d based not on their own judgment, but on the judgment of others, i.e. based on "what the Web says" of d. This of course involves using what hubs and super-hubs say of d.
Both Theseus and Google do not avoid using super-hubs and might thus be characterized as parasitical.
We described an approach to the automatic categorization of documents, which exploits contextual information extracted from an analysis of the HTML structure of Web documents as well as the topology of Web. The results of our experiments with a prototype categorization tool are quite encouraging. By exploiting information from several sources, the tool achieves an effective and accurate automatic categorization of Web documents.
The tool may evolve by incorporating further linguistic knowledge and techniques for learning category profiles.
Automatic categorization is a complex task and categorization by context is a useful technique that complements the traditional techniques based on content of documents.
[ACAB] Attardi, G., Gulli, A.: "Towards automated categorization and abstracting of Web sites", submitted for publication.
[Altavista] AltaVista,
http://altavista.digital.com.[Arianna] Arianna,
http://arianna.it.[Attardi 98] Attardi, G., Di Marco, S., Salvi, D.: "Categorization by context", Proc. of WebNet ’98, Orlando, USA, and Journal of Universal Computer Science, 4(9):719–736, (1998).
Available:
[Autonomy] Autonomy,
http://www.autonomy.com.[Brin 98] Brin, S., Page, L.: "The anatomy of a large-scale hypertextual Web search engine"; Computer Networks and ISDN Systems, 30 (1998) 107–117.
[Bookstein 76] Bookstein, A., Cooper, W.S.: "A general mathematical model for information retrieval systems", Library Quarterly, 46 (1976) 153–167.
[Chalmers 98] Chalmers, M., Rodden, K., Brodbeck, D.: "The order of things: activity-centred information access"; Computer Networks and ISDN Systems, 30 (1998), 359–367.
[Chakrabarti 98] Chakrabarti, S., Dom, B., Gibson, D., Kleinberg, J., Raghavan, P., Rajagopalan, S.: "Automatic resource list compilation by analyzing hyperlink structure and associated text"; Proc. 7th International World Wide Web Conference, 30:65–74 (1998). Available:
http://www7.conf.au/programme/fullpapers/1898/com1898.html[Chakrabarti 98a] Soumen Chakrabarti, 1998. Personal communication.
[Cleverdon 84] Cleverdon, C.: "Optimizing convenient online access to bibliographic databases"; Information Services and Use. 4 (1984), 37–47.
[Excite] Excite,
http://excite.com.[Fuhr 91] Fuhr, N., Buckley, C. A.: "Probabilistic Approach for Document Indexing"; ACM Transactions on Information Systems, 9, 3 (1991), 223–248.
[Fuhr 91a] Fuhr, N., Hartmann, S., Knorz, G., Lustig, G., Schwantner, M., Tzeras, K.: "{AIR/X} – a rule-based multistage indexing system for large subject fields"; Proceedings of RIAO'91, 3rd International Conference "Recherche d'Information Assistee par Ordinateur", Barcelona, ES, 1991, 606–623.
[Guglielmo 96] Guglielmo, E.J., Rowe, N.: "Natural-language retrieval of images based on descriptive captions"; ACM Transactions on Information Systems, 14, 3 (1996), 237–267.
[Harmandas 97] Harmandas, V., Sanderson, M., Dunlop, M.D.: "Image retrieval by hypertext links"; Proceedings of SIGIR-97, 20th ACM International Conference on Research and Development in Information Retrieval, Philadelphia, US, 1997, 296–303.
[HotBot] HotBot,
http://hotbot.com.[HTML] "HTML Primer"; NCSA. Available:
http://www.ncsa.uiuc.edu/General/Internet/WWW/HTMLPrimerAll.html.[InQuizit] InQuizit,
http://www.inquizit.com.[Ittner 95] Ittner, D.D., Lewis, D.D., Ahn, D.: Text categorization of low quality images. In Proceedings of SDAIR-95, 4th Annual Symposium on Document Analysis and Information Retrieval,, Las Vegas, US, 1995, 301–315.
[Jansen 98] Jansen, B.J., Spink, A., Bateman, J.: "Searches, the subjects they search, and sufficiency: a study of a large sample of Excite searches", WebNet ’98, Orlando, USA, (1998).
[Kessler 63] Kessler, MM.: "Bibliographic coupling between scientific papers". American Documentation, 14 (1963), 10–25.
[Lewis 96] Lewis, D.D., Schapire, R.E., Callan, J.P., Papka, R.: Training algorithms for linear text classifiers. In Proceedings of SIGIR-96, 19th ACM International Conference on Research and Development in Information Retrieval, Zürich, CH, 1996, 298–306.
[Li 98] Yanhong Li. Toward a qualitative search engine. IEEE Internet Computing, 2(4):24–29, 1998.
[Lycos] Lycos,
http://www.lycos.com.[Miller 95] Miller, G.A.: "WordNet: a lexical database for English"; Communications of the ACM, 38, 11 (1995), 39–41.
[Ng 97] Ng, H.T., Goh, W.B., Low, K.L.: "Feature selection, perceptron learning, and a usability case study for text categorization"; Proceedings of SIGIR-97, 20th ACM International Conference on Research and Development in Information Retrieval, Philadelphia, USA (1997), 67–73.
[Northern Light] Northern Light,
http://www.northernlight.com.[Page 98] Page, L.:The PageRank citation ranking: bringing order to the Web. Ann. Meeting of America Soc. Info. Sci. (1998).
[Salton 75] Salton, G., Wong, A., Yang, C.S.: "A vector space model for automatic indexing"; Communications of the ACM, 18 (1975), 613–620.
[Salton 88] Salton, G., Buckley, C.: "Term-weighting approaches in automatic text retrieval"; Information processing and management, 24 (1988), 513–523.
[Savoy 97] Savoy, J.: Citation schemes in hypertext information retrieval. In M. Agosti and A.F. Smeaton, editors, Information Retrieval and Hypertext, Kluwer Academic Publishers, Dordrecht, NL, 1997, 99–120.
[Schmid 94] Schmid, G.: "TreeTagger – a language independent part-of-speech tagger", (1994). Available:
http://www.ims.uni-stuttgart.de/Tools/DecisionTreeTagger.html.[Schütze 95] Schütze, H., Hull, D.A., Pedersen, J.O.: "A comparison of classifiers and document representations for the routing problem"; Proceedings of SIGIR-95, 18th ACM International Conference on Research and Development in Information Retrieval, Seattle, USA (1995), 229–237.
[Shrihari 95] Srihari, R.K.: "Automatic Indexing and Content-Based Retrieval of Captioned Images"; Computer, 28, 9 (1995), 49–56.
[Teseo] Teseo,
http://medialab.di.unipi.it/Project/Arianna/Teseo.[Tilton 95] Tilton, E.: "Composing Good HTML"; CMU, Pittsburgh, USA. Available:
http://www.cs.cmu.edu/People/tilt/cgh[Weiss 96] Weiss, R., Velez, B., Sheldon, M.A., Nemprempre, C., Szilagyi, P., Duda, A., Gifford, D.K.: "HyPursuit: A Hierarchical Network Search Engine that Exploits Content-Link Hypertext Clustering"; Proceedings of the Seventh ACM Conference on Hypertext, Washington, USA (1996).
[Yahoo] Yahoo!,
http://yahoo.com.[Yang 94] Yang, Y.: "Expert network: effective and efficient learning from human decisions in text categorisation and retrieval"; Proceedings of SIGIR-94, 17th ACM International Conference on Research and Development in Information Retrieval, Dublin, IE (1994), 13–22.
[Yang 97] Yang, Y.: An evaluation of statistical approaches to text categorization. Technical Report CMU-CS-97-127, School of Computer Science, Carnegie Mellon University, Pittsburgh, US, 1997. Forthcoming on Information Retrieval Journal.
Acknowledgments
We thank Antonio Converti, Domenico Dato, Luigi Madella, for their support and help with Arianna and other tools.
This work has been partly funded by the European Union, project TELEMATICS LE4-8303 EUROsearch.