numero 3 - mar/apr 1997
|
numero 3 - mar/apr 1997 |
networking |
Abbiamo visto come instradare un pacchetto in una Lan. Ma cosa succede quando un pacchetto deve attraversare più router per arrivare a destinazione?
Nel precedente numero abbiamo descritto come avviene l'instradamento
all'interno di una lan ed il modo in cui viene individuato un gateway nel caso
sia necessario comunicare con macchine presenti su reti non locali. Nel
presente articolo ci occuperemo della situazione più complessa in cui un
messaggio debba attraversare molteplici router prima di arrivare alla
destinazione. Come vedremo, i meccanismi adottati per svolgere questo compito
sono molteplici e la maggior parte di essi hanno subito una notevole evoluzione
nel tempo, rendendone alcuni oramai obsoleti.
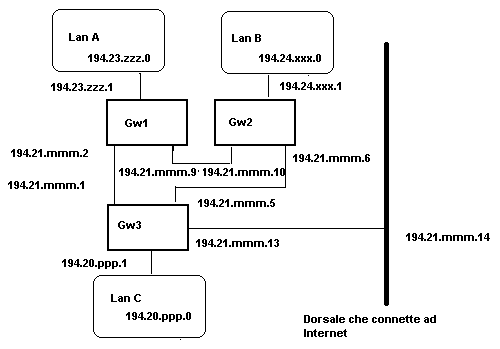
Routing dalla sorgente (source routing)Il routing dalla sorgente, come suggerisce lo stesso nome, prevede che l'host mittente indichi in maniera esplicita tutte le strade da compiere per consegnare il messaggio che sta inviando. All'interno del pacchetto IP vengono dunque specificati in una lista tutti gli address da attraversare. L'ultima indicazione presente corrisponde all'host destinatario.Del source routing (SR) esistono due versioni distinte: la prima, più vincolante, prevede che possano essere attraversati solo i gateway e gli host espressamente indicati nella lista di address che accompagna ogni pacchetto; la seconda consente di raggiungere le macchine indicate utilizzandone altre non espressamente menzionate. Il modello (SR) viene riportato solo per completezza in quanto superato da schemi che adattano il proprio comportamento in base al carico locale di ogni gateway attraversato. Le operazioni di base del routing tra gatewayNel modello correntemente adottato dalla comunità Internet si prevede che all'interno di ogni gateway sia presente una tab di routing contenente, in prima istanza, una voce per ogni rete raggiungibile e l'indirizzo del router attraverso cui raggiungerla (neighbor router). La creazione e la gestione di queste tab può avvenire staticamente o dinamicamente, mediante l'utilizzo di protocolli opportuni.Un concetto che sta alla base delle operazioni di instradamento svolte da ogni router IP è quello di metrica. Con tale termine si designa un fattore che permette di scegliere tra due o più strade alternative per raggiungere la destinazione desiderata. In molti contesti la metrica adottata è la più semplice possibile: quella della distanza. Essa non è altro che il conteggio del minor numero di salti , in gergo detti "hop", che è necessario compiere dal gateway corrente per arrivare alla destinazione scegliendo una strada piuttosto che un altra. Il funzionamento di un router IP è fondamentalmente molto semplice: si tratta di individuare, per ogni pacchetto ricevuto, la migliore interfaccia fisica di uscita tra quelle presenti sulla macchina. A tale scopo, per ogni datagram (pacchetto) si consulta la tab di routing (TR, da ora in poi) cercando una corrispondenza tra l'indirizzo di rete di destinazione e le entry che TR contiene. Se la corrispondenza viene trovata il router, la utilizza per determinare la porta di uscita. Nel caso in cui le corrispondenze siano più d'una il router utilizza quella con metrica migliore. Se, al contrario, non viene individuata alcuna entry utile, l'evento è segnalato all'host che aveva generato il datagram con un messaggio ICMP di tipo "destinazione non raggiungibile". Lo stesso datagram viene semplicemente scartato. Vediamo di focalizzare quanto sin qui detto con un esempio significativo. In figura 1 è rappresentata una inter-net costituita da tre LAN connesse da tre router mediante la rete 194.21.mmm.0 opportunamente subnettata. La lan 194.20.ppp.0 raggiunge, ad esempio, la lan 194.24.xxx.0 sia passando attraverso la coppia di gateway (GW3 - GW2) sia passando la tripla di gateway (GW3 - GW1 - GW2). Se le informazioni di routing in tab del GW3 vengono create staticamente si può pensare di inserire due entry relative alla lan 194.21.mmm.0: una avente come "neighbor router" l'IP 194.21.mmm.2 dell'interfaccia seriale del GW1 e l'altra avente come "neighbor router" l'IP 194.21.mmm. 6. Lo scopo è quello di raggiungere, partendo dalla lan A, la lan B attraverso il percorso preferenziale che effettua soltanto due "hop" ma utilizzando, in via alternativa come link di back-up, il percorso con tre "hop" se per qualche motivo il primo divenisse improvvisamente non disponibile. Come avrete capito il trucco è quello di settare la metrica più bassa alla entry che si preferisce usare in via preferenziale. Su un router Cisco con IOS 11.0 questo effetto è ottenuto utilizzando, in modalità di configurazione globale, il comando:
ip route "network" [mask]
{ address | interface } [distance]
Avevamo già descritto questo statement, in via sommaria, nei precedenti
numeri e adesso abbiamo tutti gli elementi per darne una presentazione formale.
Il comando ip route accetta come parametri la rete da inserire in
tab di routing assieme alla eventuale mask che la caratterizza, l'indirizzo
della interfaccia di uscita (o semplicemente il suo nome se essa è
lasciata "unnumbered") ed infine il parametro che caratterizza il
peso da dare alla informazione da creare in tab.
Ecco come configurare Gw3 utilizzando metriche distinte per la stessa rete destinazione: ip route 194.23.zzz.0 255.255.255.0 194.21.mmm.2 10 ip route 194.23.zzz.0 255.255.255.0 194.21.mmm.6 20 ip route 194.24.xxx.0 255.255.255.0 194.21.mmm.6 10 ip route 194.24.xxx.0 255.255.255.0 194.21.mmm.2 20 ip route 0.0.0.0 0.0.0.0 194.21.mmm.14Il Cisco mantiene in tab le informazioni associate ad una interfaccia fintanto che essa rimane funzionante. In caso di caduta di un link fisico, le entry associate vengono immediatamente rimosse. In tale modo, se improvvisamente il link che connette direttamente Gw3 e Gw2 si interrompe, la lan B viene comunque raggiunta passando attraverso il Gw1. Nel listato 1 vengono riportate tutte le configurazioni necessarie al corretto funzionamento dei tre router. Una osservazione particolarmente importante è il fatto che le reti direttamente connesse ("connected") quali quella cui appartiene l'IP della Ethernet del gateway non richiedono informazioni esplicite circa l'instradamento. Ad esempio il router GW3 crea in modo automatico una entry come se gli venisse imposto il comando ip route 194.20.ppp.0 2555.255.255.0 194.20.ppp.1. La metrica associata in questo caso è il valore zero (volutamente il più basso possibile)
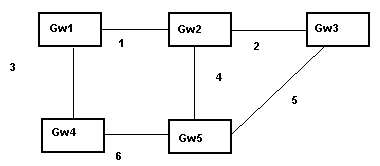
Tabelle di Routing: Formato MIBPrima di proseguire ulteriormente credo sia il caso di dare una definizione precisa di quali siano i campi contenuti all'interno della tavola di routing.La proposta di standardizzazione è stata compiuta dalla Internet Activities Board (IAB) nella RFC 1213. Una ricostruzione è riportata nel riquadro 1. La MIB table (da Management Information Base) consiste di una riga per ogni host o rete da raggiungere; a ciascuna riga sono associate molteplici informazioni mantenute per colonna. Analizziamole in dettaglio: Il campo destinazione contiene l'IP address dell'host o della rete che si vuole raggiungere. Se è presente la chiave 0.0.0.0 allora che le informazioni contenute nelle colonne adiacenti devono essere usate per qualunque pacchetto che non si sappia trattare con le regole inserite in differenti righe. La colonna Ifindex rappresenta un indice per l'interfaccia fisica attraverso il quale può esser raggiunto il neighbor router che permette di "avvicinarsi" alla destinazione. Le cinque colonne restanti sono relative alla metrica. Come vedremo alcuni protocolli, tra cui OSPF, scelgono il cammino da percorrere basandosi su differenti funzioni di costo. La colonna successivo indica l'indirizzo IP del neighbor router. Spesso essa viene usata in alternativa alla colonna IfIndex. Il campo Tipo di Cammino distingue tra reti direttamente connesse (quali la lan B rispetto al GW3), reti raggiungibili indirettamente (quali la lan C sempre rispetto GW3) e reti non raggiungibili. Il campo Protocollo di Routing identifica mediante l'utilizzo di una chiave unica il protocollo di routing che ha originato la entry (RIP, OSPF, IGRP, BGP) La colonna Durata indica il tempo necessario ad acquisire oppure ad aggiornare la entry. Il campo Maschera è utilizzato con una operazione di AND Bit - a - Bit per individuare il Network Number associato all'IP destinazione. Utilizzandolo opportunamente è possibile inserire molteplici informazioni di routing per una medesima rete di classe fissata. Il campo Informazioni viene usato in modo differente da ogni singolo protocollo di routing. Una digressione: il subnettingApprofitto della definizione formale del la tavola MIB per ritornare sull'argomento del subnetting, spiegando il modo in cui viene gestito attraverso le tab di routing.Immaginiamo di trovarci nella situazione di un provider che abbia ricevuto una rete di classe C e voglia ripartirla in due parti distinte: una da assegnare alla propria rete ethernet locale ed una ad un POP remoto connesso, ad esempio, con interfaccia asincrona. Di seguito riportiamo come fare: ! interface Ethernet0 description "this side of the moon" ip address 194.20.mmm.1 255.255.255.128 ip broadcast-address 194.20.116.127 ! interface Async7 description "The other side of the moon" ip address 194.21.mmm.205 255.255.255.252 ip broadcast-address 194.21.mmm.207 async mode dedicated ! ip route 194.20.mmm.128 255.255.255.128 194.21.mmm.206 ! line 7 location "Near the moon" exec-timeout 5 0 no history no editing transport output none stopbits 1 speed 57600 flowcontrol hardwareIl Cisco, configurato nel modo di sopra riportato, genera nella tavola MIB due entry relative alla rete 194.20.mmm.X. La prima, grazie al comando esplicito "ip route", ha il mask 255.255.255.128 per la porzione che parte dall'indirizzo 194.20.mmm.128 e si estende progressivamente per 128 indirizzi; l'altra ricavata automaticamente grazie al fatto che l'interfaccia ethernet ha come ip 194.20.mmm.1 con mask 255.255.255.128. Il cisco comprende che i primi 128 indirizzi della rete 194.20.mmm.X appartengono ad una sottorete direttamente connessa. Sottolineo che le due porzioni di sottorete risultano distinte allo stesso modo in cui lo sono due reti che, pur appartenendo alla stessa classe (A,B,C), abbiano ip diverso. Questo perché l'utilizzo del subnet mask 255.255.255.255.128 applicato ad una generica rete di classe C indica, come spiegato nel precedente articolo, che il Network Number è costituito oltre che dai primi tre ottetti dell'indirizzo 194.20.mmm.X anche dal bit iniziale del quarto ottetto. Tutte queste informazioni vengono mantenute nella tavola MIB di ogni router; grazie ad esse ogni gateway costruisce una entry di instradamento per ogni Network Number distinto. Le creazione dinamica delle tabelle di routingGiungiamo adesso al cuore dell'articolo partendo da alcune considerazioni su quanto sin qui fatto. Al momento abbiamo sviluppato una metodologia che ci consente, per lo meno in linea teorica, di interconnettere tra loro un numero anche alto di lan.A ciascuna di esse viene associata una interfaccia di uscita per ciascun router che viene attraversato. In caso di molteplici percorsi si ricorre ad una differente metrica impostata manualmente sulla base di considerazioni topologiche note a priori. Una analisi attenta permette , tuttavia, di sottolineare alcune problematiche. Innanzi tutto al crescere delle lan da collegare, L1 , ... Lm , mediante una rete di routers R1, ... , Rn (con m generalmente molto più grande di n) cresce in modo altrettanto veloce la possibilità di commettere qualche errore in un particolare router. Il risultato che si produce è un effetto negativo sulla raggiungibilità reciproca delle singole parti delle lan. Un problema, affine a quello dell'errore, che si verifica in ambienti di networking eterogeneo è il grosso lavoro di coordinamento necessario per la configurazione di router spesso gestiti da network manager appartenenti ad istituzioni distinte. Se queste prime due considerazioni possono apparire superabili, ne rimane una che deve necessariamente essere risolta in modo elegante e funzionale. Ogni Router vede crescere la propria tab di routing in maniera lineare rispetto al numero di reti da instradare direttamente. Questo pone, data la crescita attuale di Internet, notevoli problemi di dimensionamento delle risorse e di obsolescenza Nei primi anni ottanta, Internet era considerata come una "single network" (SN) distinta da quella rappresenta in figura 1 solo per dimensioni delle reti collegate. L'introduzione di sistemi che permettessero ai router di adattarsi dinamicamente al mutare della tipologia di connessione costituiva una soluzione parziale al problema. Se da una parte diminuiva il tasso di errore e la necessità di coordinamento umano, aumentando contemporaneamente la tolleranza ai guasti delle singole connessioni, dall'altra ci si rese conto che questa scelta non risolveva il problema della crescita delle tab di routing. La decisione intrapresa fu quella di abbandonare il modello SN per suddividere Internet in un certo numero di Autonomous System (AS) "costituiti da un insieme di router e lan sotto la medesima amministrazione". Questa definizione, non molto flessibile, è stata in seguito sostituita da una più funzionale che prevede che i router all'interno di ogni AS siano reciprocamente raggiungibili. Le informazioni di raggiungibilità sono, preferibilmente, scambiate mediante uno o più protocolli adattivi detti "Interior Protocol". Inoltre si prevede che gli AS si scambino informazioni sulla rispettiva raggiungibilità utilizzando un protocollo opportuno genericamente designato come "Exterior Protocol". Se un gateway deve instradare un messaggio ad un altro gateway appartenente allo stesso AS, avrà nella propria tavola di routing l'informazione di raggiungibilità idonea. Se al contrario è necessario raggiungere un gateway che appartiene ad un differente AS il messaggio viene inviato attraverso una coppia di router particolari detti "exterior router", almeno uno per AS. Ciascun "exterior router" conosce le reti raggiungibili utilizzando i link che lo collegano agli altri "exterior router" ma non conosce il modo in cui queste reti sono di fatto connesse all'interno dei rispettivi AS (secondo un modello tipicamente gerarchico). Nel seguito dell'articolo daremo le basi teoriche e di configurazione pratica del RIP, cioè uno dei più semplici algoritmi di instradamento Intra-AS. Nel numero successivo ci occuperemo di OSPF e di E-IGRP, protocolli più evoluti che risolvono i problemi che il RIP presenta se utilizzato su vasta scala. Routing Internet Protocol (RIP)Il RIP è definito formalmente nella RFC-1058. Esso è un protocollo basato sull'algoritmo sviluppato da Bellman[1]. La classe di protocolli che utilizzano questi algoritmi va sotto il nome di "vector distance". Vediamone un esempio basandoci sulla figura 2.Siamo in presenza di 5 gateway (Gwi) connessi tra di loro mediante 6 link. Inizialmente ciascun Gwi conosce solo il proprio indirizzo ed i link che lo connettono ai restanti Gw. Dopo una passo ciascun gateway invia su tutti i link le informazioni di raggiungibilità di cui è in possesso. Chiunque riceva queste informazioni somma uno alla metrica associata e se essa risulta minore di una entry già acquisita quest'ultima viene rimpiazzata. Nel caso del RIP la metrica è dunque molto semplice: la distanza non è altro che il numero di link che devono essere utilizzati per raggiungere la destinazione. Per questa ragione, ogni volta che un router viene attraversato, alla metrica associata alla entry presente nel link di entrata viene sommato uno. Quindi al passo zero GW1 e GW2, ad esempio, conoscono solo le informazioni locali a se stessi (tabella 1.1). Dopo un passo GW2 acquisisce le informazioni di raggiungibilità inviategli da GW1; lo stesso accade, ad esempio, per GW4 ed GW1 (tabella 1.2). Compiuto un ulteriore passo GW5 apprende che GW1 può essere raggiunto con costo due sia attraverso il link 3 sia attraverso il link 4. Delle due entry (essendo entrambe di pari peso una viene scartata). Dopo un certo numero di step l'algoritmo converge e ogni singolo router scopre autonomamente la tipologia della rete cui è connesso.
Caduta di un link: stato temporaneo di inconsistenzaSempre riferendo la figura 2, supponiamo che link 2 improvvisamente smetta di funzionare. La condizione viene immediatamente rilevata da GW2 , fisicamente connesso a tale linea, che aggiorna la propria tab di routing settando la metrica associata ad infinito (che per convenzione è la distanza 16), segnalando sui link in uscita questa modifica avvenuta alla topologia della rete.In prima analisi il RIP non setta degli intervalli durante i quali procedere agli update delle tavole di routing: al contrario, gli scambi di informazioni tra i GW avvengono in maniera non deterministica. Per questa ragione, può accadere che prima che GW2 abbia inviato la nuova tab di routing a GW1, questi abbia nuovamente spedito a GW2 la propria tavola nonaggiornata contenente la vecchia informazione che GW3 può essere raggiunto sul link 1 con metrica 2. GW2 ricevendo questa informazione porta la metrica associata a 3 e poiché tale valore è inferiore di infinito suppone che GW3 sia raggiungibile con tale costo attraverso il link 1. Il ciclo ricomincia quando GW2 reinvia a GW1 la nuova metrica (3) associata al link 1. Sul link 1 si avrà un continuo scambio di pacchetti relativi ad informazioni di raggiungibilità del GW3. La metrica associata aumenterà di uno ad ogni passo sino giungere ad infinito. Per tutto questo tempo quello che si sarà creato è un loop: GW1 invia a GW2 i pacchetti che deve inviare a GW3 ; GW2 rispedisce a GW1 i pacchetti destinati a GW2. Questo stato temporaneo viene superato, dopo un certo numero di passi, non appena l'algoritmo converge nuovamente su tutti i nodi. Non riportiamo, per brevità, tutti gli step ma ci limitiamo a sottolineare come questo stato sia altamente pericoloso perché comporta perdita di pacchetti (tra cui, spesso, le stesse informazioni di routing) e congestione sui link. Caduta di due link: maggiore inconsistenzaComplichiamo un pò le cose e supponiamo che contemporaneamente i link 1 e 6 non siano più utilizzabili e che, di conseguenza, i gateway GW1 e GW4 siano isolati dai gateway GW2 GW3 GW5.Supponiamo che GW4 si accorga per primo della caduta del link 6 aggiorni la propria tavola ma non riesca, come nell'esempio precedente, a trasmetterla a GW1 prima di ricevere le sue informazioni. Nuovamente si verifica un loop ma questa volta non vi è possibilità di convergere ad una nuova soluzione perché anche il link 1 è interrotto. Le informazioni corrette non hanno, dunque, la possibilità di fluire attraverso questa interfaccia. Come nel caso precedente si produce congestione e perdita di pacchetti. Le metriche associate ad un percorso andato in loop continuano a crescere, un passo dopo l'altro. Per risolvere la situazione si suppone che, fissato un valore ritenuto sufficientemente alto, il link la cui metrica supera tale valore sia ritenuto amministrativamente inaccessibile. In linguaggio tecnico questa strategia è detta : "counting to infinity" Alcune modifiche all'algoritmo inizialePer tentare di ovviare ai problemi che l'algoritmo di Bellman presenta sono state proposte due tecniche, descriviamole brevemente.Split Horizon L'idea è molto semplice: se il gateway GW1 invia pacchetti a GW3 attraverso GW2 allora non ha senso che GW1 invii a GW2 informazioni di routing relative a GW3. Questa semplice osservazione elimina immediatamente il formarsi dei loop costituiti da due nodi ma non previene i loop più complessi ( tre o più nodi). Timers ed Triggerr Updates: Questa tecnica tenta di associare alle informazioni di instradamento anche alcune di tipo temporali. Ad ogni entry in tavola di routing è associato un meccanismo di time-out. Se l'informazione non viene aggiornata prima dello scadere del time-out il link corrispondente è ritenuto amministrativamente down. La scelta del valore di time-out è cruciale: esso deve essere di molto superiore al tempo medio necessario per effettuare l'update di tutta la topologia di rete cui il gateway è connesso (in genere 180 secondi). Se dopo 240 secondi da quando questa condizione si verifica non è ancora giunto alcun aggiornamento relativo alla entry ritenuta down, essa viene realmente rimossa dalla tavola di routing. Un altro timer (settato a 30 secondi) viene utilizzato per decidere il momento in cui fare fluire la propria tavola di routing attraverso i link in uscita. La richiesta di informazioni può esser forzata, da parte di un singolo router, mediante una tecnica detta "trigger update". Per evitare che tutti i router interrogati rispondano contemporaneamente si prevede che essi attendano un periodo di tempo scelto casualmente, ed in maniera indipendente l'uno dall'altro , nell'intervallo dei cinque secondi. Una ultima considerazione: originariamente si prevedeva che i router propagassero la tab di routing interamente, mentre le versioni del RIP più recenti prevedono che ogni router possa effettuare due tipi di richieste specifiche ai suoi pari; una in cui si richiede l'intero listing delle tab di routing degli altri gateway (in generale, non appena un router viene accesso), e l'altra in cui si richiedono solo le entry modificate. Aspetti implementativiIl protocollo RIP utilizza il sottostante UDP (sulla porta 520), in broadcast, per inviare le tab. Purtroppo non è prevista alcuna procedura di sicurezza né alcuna autoidentificazione. Chiunque invii dei pacchetti validi su una rete viene ritenuto un router.Su molti host Unix è prevista l'esistenza di un demone detto "routed" che utilizza il RIP in maniera passiva (tecnicamente questi host sono chiamati "silent node") per apprendere la topologia della rete e decidere quale gateway utilizzare come uscita. Questa tecnica è oramai considerata obsoleta. In alternativa il "routed" può essere utilizzato su quegli host che hanno più di un link a reti distinte (host multihomed, secondo la terminologia corrente). Purtroppo il protocollo non è molto versatile. Non è prevista una differenziazione esplicita del "Network Address" dalla parte rimanente di un indirizzo IP. Ogni gateway deve ogni volta testare un indirizzo contro la subnet mask discriminando se un Ip rappresenti una rete, una sottorete o un singolo host. Si suppone che nessuna informazione di routing relativa ad alcuna sottorete S1 , S2 , ... , Sn possa uscire ad di fuori della rete R cui essa appartiene. Configurazione di una rete di cisco adottando il RIPPassiamo ora agli aspetti pratici. Ogni network "avvertito" da un router può avere una metrica associata in un valore scelto da zero a quindici; le reti direttamente connesse (ad esempio quella corrispondente all'ip della ethernet) hanno metrica amministrativamente pari a zero.Se un router Ruscita ha un "default path" ovvero possiede una entry che lo connette al resto di internet, la pseudo-rete 0.0.0.0 viene propagata ai rimanenti router per informali che il router Ruscita è il default gateway verso le altre lan. Il Rip è un protocollo di tipo broadcast (pensato per una ethernet od un token ring ad esempio). Per consentire il corretto funzionamento su dei link di tipo point-to-point (come quelli di una seriale di un cisco) bisogna esplicitamente indicare l'ip della interfaccia remota cui si vuole fare giungere le informazioni. Questo si ottiene con il comando: neighbor ip-addressIl router viene istruito ad aprire una sessione RIP con i rimanenti mediante il semplice comando (ricordo che ogni comando può esser annullando premettendogli la forma "no") : router ripL'informazione delle reti da propagare è resa disponibile mediante il seguente comando: network "network-number"Ricordo che non è possibile propagare alcuna informazione esplicita per le sottoreti. Vediamo dunque un estratto da una configurazione tipica: ! hostname gw-rip.mydomain.it ! ... ! router rip network 131.114.0.0 network 194.21.7.0 passive-interface ethernet0 neighbor 131.114.11.1Brevemente riassumiamo cosa accade: il router gw-rip sta avvertendo il suo pari 131.114.11.1, su un link di tipo point to point, che attraverso di esso devono passare i pacchetti relativi alle due reti 131.114.0.0 (classe B) e 194.21.7.0 (classe C). Il comando passive-interface permette di evitare che le tab di routing fluiscano anche sulla interfaccia ethernet0. Il suo utilizzo mirato permette, dunque, di selezionare i link su cui fare passare le informazioni di routing. 131.114.11.1 apprende queste informazioni e le propaga ai suoi pari aumentando la metrica di uno, come descritto in precedenza. Se in una fase iniziale, quindi, ogni router conoscerà staticamente informazioni esclusivamente locali , dopo un certo periodo di tempo tutta le rete di router a cui gw-rip appartiene avrà appreso la topologia delle singole parti e sarà in grado di adattarsi dinamicamente ai suoi mutamenti. ConclusioniNei prossimi articoli presenteremo un diverso protocollo (E-IGRP), proprietario della Cisco, che usa come base l'algoritmo di Bellman: il suo utilizzo è veramente vasto. Sempre nei numeri successivi verrà presentato il protocollo OSPF considerato da più parti lo stato dell'arte per ciò che riguarda i modelli di instradamento IP adattivi. Esso appartiene ad una classe di algoritmi conosciuta come "Link State" le cui basi matematiche sono nettamente diverse (e più efficienti) di quelle degli algoritmi "distance vector".Bibliografia[1] Bellman R.E. "Dynamic Programming" Princeton University Press, Princeton, N.J. 1957 |